A decade ago, “microservices” was a specialist conversation. Today it is board relevant because the delivery and risk envelope has changed. Cloud native adoption is now mainstream in Europe, while adoption in the Middle East and Africa is accelerating from a lower base. In the CNCF Annual Survey 2024, 92% of European respondents report at least some cloud native application development and deployment, compared with 66% in the Middle East and Africa.
That matters because your operating model is now the bottleneck, not just your architecture diagram. Containers are widely used in production, Kubernetes is dominant, and multi cloud is common. At the same time, cloud costs and security exposure are climbing fast enough to force harder trade offs.
So the real question is not “monolith vs microservices”. The question is when microservices make sense for your business outcomes, your risk appetite, and your ability to run distributed systems without turning delivery into a permanent incident response exercise.
Monoliths still win more often than people admit
Microservices are not a prize for “maturity”. They are a cost model. If you are not explicit about what you are buying, you will pay for complexity and receive little in return.
A well structured monolith, often a modular monolith, can deliver excellent outcomes when these are true:
Your product change profile is coupled
If most changes require coordinated updates across multiple domains, microservices will not remove coupling, they will simply move it into APIs, events, and release choreography. In practice, that increases AIM overhead, test effort, and deployment risk.
Your primary constraint is delivery throughput, not runtime scalability
Many enterprises over rotate on “scaling”, when the actual pain is slow decision making, unclear ownership, and fragile release processes. CircleCI’s 2024 report shows teams are improving delivery benchmarks, with throughput up and recovery times down, but it also highlights that speed without stability can hide quality gaps. In that world, a monolith that is easy to reason about can be a competitive advantage.
Your integration surface is the real battlefield
Most monolith pain in enterprises comes from the perimeter: legacy systems, data replication, IAM, and audit requirements. Replatforming into microservices without fixing integration discipline is a classic “new core, same mess” outcome.
Strong opinion, based on what fails in the field: if you cannot run one service well, you will not run fifty services well. Start by making one codebase boringly reliable before multiplying the moving parts.
When microservices make sense: the decision test
This is the decision maker test for when microservices make sense. If you cannot tick at least three of these boxes with evidence, you are likely better off modernising your monolith first.
1) Independent business domains with real autonomy
You have domains where teams can make changes without synchronising with everyone else. That usually means: separate backlogs, separate release cadence, and clear product ownership. If “everything touches everything”, microservices make sense only after you fix domain boundaries.
2) Non negotiable scalability or isolation requirements
You have workloads where isolation is a hard requirement: noisy neighbours, regulatory segregation, or elastic demand that is expensive to overprovision. This is most compelling in high variability channels: customer onboarding bursts, payments spikes, logistics tracking peaks.
3) A platform capability already exists, or can be funded
Microservices make sense when you can standardise the plumbing. The CNCF Annual Survey 2024 shows containers in production are now normalised, with 91% of organisations using containers in production. Kubernetes production usage is also high, with 80% using Kubernetes in production and 93% using it, piloting it, or evaluating it. That is the enabling layer, not the finish line. The finish line is observability, CI/CD guardrails, security automation, and cost controls that work without heroics.
4) Cloud cost management is part of the architecture decision
If you move to microservices, you will create more deployable units, more environments, and more telemetry. That increases cost surface area. Flexera’s 2025 State of the Cloud press release reports 84% of respondents say managing cloud spend is the top challenge, and cloud spend is expected to increase by 28% in the coming year. If you cannot measure unit economics per service, microservices make sense only if the business value dwarfs the waste risk.
5) You are fixing risk, not chasing fashion
Gartner predicts 25% of organisations will experience significant dissatisfaction with their cloud adoption by 2028 due to unrealistic expectations, suboptimal implementation, or uncontrolled costs. Microservices often amplify those exact failure modes when they are adopted as a trend. When microservices make sense is when they are an explicit risk management choice, for example blast radius reduction, controlled change, and measurable resilience.
Architecture, data, and security implications executives should force into the plan
When microservices make sense, the architecture decision immediately becomes a data and security decision.
Integration patterns: APIs, events, and the “truth” problem
Microservices create more integration edges. You must choose where truth lives and how it propagates. Most enterprises end up with a mix:
- Synchronous APIs for read and command patterns that need immediate feedback.
- Events for resilience and decoupling.
- Batch for legacy alignment.
The failure mode is “distributed spaghetti”, where every team invents its own API style, auth scheme, and retry logic. The mitigation is standards plus paved roads: consistent API contracts, versioning rules, idempotency expectations, and shared libraries only where they reduce risk.
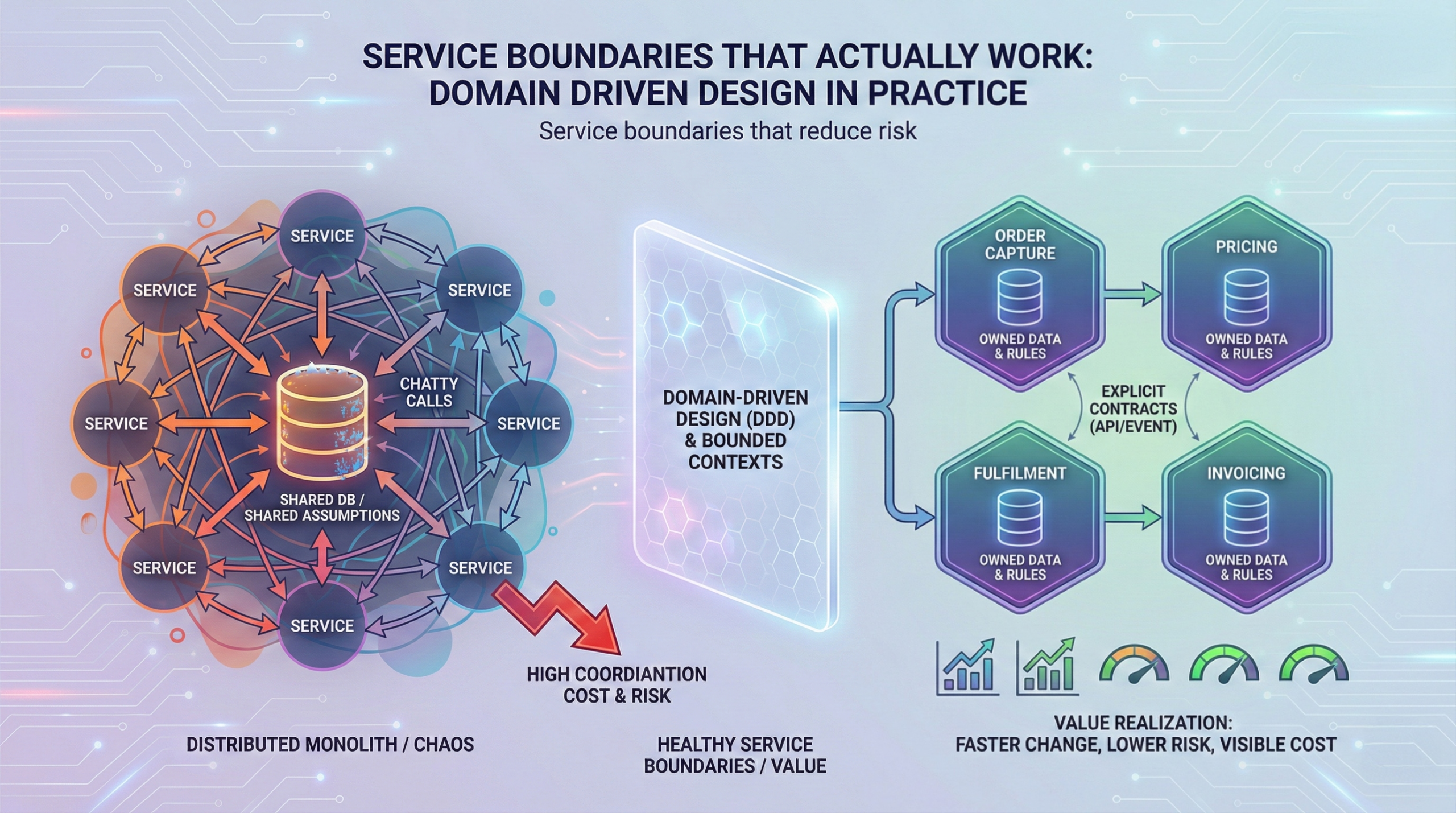
Data ownership: you cannot scale microservices on shared tables
If services share a database schema, you have a distributed monolith with extra failure modes. A microservices programme should include a data product strategy: owned data per domain, defined sharing mechanisms, and governance around PII and retention. This is where many transformations stall because legacy reporting expects a single enterprise schema.
Security: distributed systems expand the attack surface
The IBM Cost of a Data Breach Report 2024 puts the average cost of a breach at USD 4.88 million, up 10% year on year. For the Middle East, the report lists USD 8.75 million as the average breach cost, second only to the United States in its country and region table. More services means more identities, more secrets, more APIs, and more policy. Treat that as a core programme stream, not a checklist at the end.
Practical governance guardrail: no service goes live without automated security testing in the pipeline, production grade secrets management, and standardised logging that can support audit and incident response.
Operating model and governance: what must change so microservices do not turn into chaos
Microservices are an operating model upgrade disguised as an architecture initiative.
Accountability moves from “project” to “product”
A service should have a clear owner, a lifecycle, and an SLO. Without that, on call becomes a blame game.
Platform engineering becomes a force multiplier
CircleCI’s 2024 release notes call out platform engineering as an emerging practice that helps scale effective delivery practices. In a microservices context, platform engineering is the difference between “every team builds their own pipeline” and “teams ship safely by default”.
Governance becomes lighter but more enforceable
You need fewer design review meetings and more automated controls. The governance stack that works:
- Architecture guardrails: reference architectures, approved patterns, golden paths.
- Policy as code: security and compliance controls enforced in CI/CD.
- FinOps controls: tagging, budgets, and service level cost reporting.
Anonymised example: an EU insurer moved from a quarterly release train to weekly releases by first standardising CI/CD, observability, and incident playbooks on the monolith. Only then did they carve out two domains into services. The early win was not “microservices”. The win was predictable change with measurable downtime reduction.
Implementation approach: phases, guardrails, and typical failure modes
If you decide when microservices make sense for your context, treat migration as a phased capital allocation decision.
Phase 0: Stabilise and instrument the monolith
Before extraction, define service boundaries and measure baseline KPIs:
- Lead time for change
- Deployment frequency
- Change failure rate
- Mean time to recovery
- Business KPIs: conversion, cycle time, cost per transaction, customer satisfaction
This is where many teams discover the monolith is not the issue. The issue is missing telemetry and unclear ownership.
Phase 1: Carve out one high value domain
Pick a domain with clear boundaries and measurable business value. Typical candidates: notifications, document generation, payments adapters, workflow orchestration components.
Guardrails:
- Contract first APIs
- Centralised identity and access patterns
- Standardised logging, tracing, and alerting
Phase 2: Build the “paved road” and repeat
Scale by standardising:
- Service templates
- CI/CD pipelines with policy gates
- Observability standards
- Cost and tagging standards
Phase 3: Rationalise data and reduce coupling
This is the hard part. Data migration, reporting rework, and event driven consistency take time. If you skip this, you will stall.
Typical failure modes you should plan against:
- “Too many services too soon” and no platform
- Shared database persistence that blocks autonomy
- No SLO ownership, resulting in constant escalations
- Cost blowouts because environments and telemetry sprawl
- Security gaps due to inconsistent IAM and secrets handling
Anonymised example: a MENA logistics firm split into microservices to “go faster”, but kept a shared database for reporting. They gained deployment complexity without autonomy. The turnaround was to introduce bounded context ownership and move reporting to a governed analytical layer, which finally allowed independent releases.
Actionable Takeaways
- Start with the decision test. Only proceed when microservices make sense for at least three business driven reasons.
- Stabilise the monolith first. Instrumentation and ownership often unlock more value than a rewrite.
- Treat platform engineering as mandatory, not optional.
- Fund FinOps and security as part of the architecture, not as overhead.
- Define data ownership early. Shared tables kill autonomy.
- Standardise contracts and observability before scaling service count.
- Measure value realisation using delivery metrics plus business KPIs, not architecture milestones.
- Migrate in thin slices with rollback paths, not big bang replatforming.
A decade ago, “microservices” was a specialist conversation. Today it is board relevant because the delivery and risk envelope has changed. Cloud native adoption is now mainstream in Europe, while adoption in the Middle East and Africa is accelerating from a lower base. In the CNCF Annual Survey 2024, 92% of European respondents report at least some cloud native application development and deployment, compared with 66% in the Middle East and Africa.
That matters because your operating model is now the bottleneck, not just your architecture diagram. Containers are widely used in production, Kubernetes is dominant, and multi cloud is common. At the same time, cloud costs and security exposure are climbing fast enough to force harder trade offs.
So the real question is not “monolith vs microservices”. The question is when microservices make sense for your business outcomes, your risk appetite, and your ability to run distributed systems without turning delivery into a permanent incident response exercise.
Monoliths still win more often than people admit
Microservices are not a prize for “maturity”. They are a cost model. If you are not explicit about what you are buying, you will pay for complexity and receive little in return.
A well structured monolith, often a modular monolith, can deliver excellent outcomes when these are true:
Your product change profile is coupled
If most changes require coordinated updates across multiple domains, microservices will not remove coupling, they will simply move it into APIs, events, and release choreography. In practice, that increases AIM overhead, test effort, and deployment risk.
Your primary constraint is delivery throughput, not runtime scalability
Many enterprises over rotate on “scaling”, when the actual pain is slow decision making, unclear ownership, and fragile release processes. CircleCI’s 2024 report shows teams are improving delivery benchmarks, with throughput up and recovery times down, but it also highlights that speed without stability can hide quality gaps. In that world, a monolith that is easy to reason about can be a competitive advantage.
Your integration surface is the real battlefield
Most monolith pain in enterprises comes from the perimeter: legacy systems, data replication, IAM, and audit requirements. Replatforming into microservices without fixing integration discipline is a classic “new core, same mess” outcome.
Strong opinion, based on what fails in the field: if you cannot run one service well, you will not run fifty services well. Start by making one codebase boringly reliable before multiplying the moving parts.
When microservices make sense: the decision test
This is the decision maker test for when microservices make sense. If you cannot tick at least three of these boxes with evidence, you are likely better off modernising your monolith first.
1) Independent business domains with real autonomy
You have domains where teams can make changes without synchronising with everyone else. That usually means: separate backlogs, separate release cadence, and clear product ownership. If “everything touches everything”, microservices make sense only after you fix domain boundaries.
2) Non negotiable scalability or isolation requirements
You have workloads where isolation is a hard requirement: noisy neighbours, regulatory segregation, or elastic demand that is expensive to overprovision. This is most compelling in high variability channels: customer onboarding bursts, payments spikes, logistics tracking peaks.
3) A platform capability already exists, or can be funded
Microservices make sense when you can standardise the plumbing. The CNCF Annual Survey 2024 shows containers in production are now normalised, with 91% of organisations using containers in production. Kubernetes production usage is also high, with 80% using Kubernetes in production and 93% using it, piloting it, or evaluating it. That is the enabling layer, not the finish line. The finish line is observability, CI/CD guardrails, security automation, and cost controls that work without heroics.
4) Cloud cost management is part of the architecture decision
If you move to microservices, you will create more deployable units, more environments, and more telemetry. That increases cost surface area. Flexera’s 2025 State of the Cloud press release reports 84% of respondents say managing cloud spend is the top challenge, and cloud spend is expected to increase by 28% in the coming year. If you cannot measure unit economics per service, microservices make sense only if the business value dwarfs the waste risk.
5) You are fixing risk, not chasing fashion
Gartner predicts 25% of organisations will experience significant dissatisfaction with their cloud adoption by 2028 due to unrealistic expectations, suboptimal implementation, or uncontrolled costs. Microservices often amplify those exact failure modes when they are adopted as a trend. When microservices make sense is when they are an explicit risk management choice, for example blast radius reduction, controlled change, and measurable resilience.
Architecture, data, and security implications executives should force into the plan
When microservices make sense, the architecture decision immediately becomes a data and security decision.
Integration patterns: APIs, events, and the “truth” problem
Microservices create more integration edges. You must choose where truth lives and how it propagates. Most enterprises end up with a mix:
- Synchronous APIs for read and command patterns that need immediate feedback.
- Events for resilience and decoupling.
- Batch for legacy alignment.
The failure mode is “distributed spaghetti”, where every team invents its own API style, auth scheme, and retry logic. The mitigation is standards plus paved roads: consistent API contracts, versioning rules, idempotency expectations, and shared libraries only where they reduce risk.
Data ownership: you cannot scale microservices on shared tables
If services share a database schema, you have a distributed monolith with extra failure modes. A microservices programme should include a data product strategy: owned data per domain, defined sharing mechanisms, and governance around PII and retention. This is where many transformations stall because legacy reporting expects a single enterprise schema.
Security: distributed systems expand the attack surface
The IBM Cost of a Data Breach Report 2024 puts the average cost of a breach at USD 4.88 million, up 10% year on year. For the Middle East, the report lists USD 8.75 million as the average breach cost, second only to the United States in its country and region table. More services means more identities, more secrets, more APIs, and more policy. Treat that as a core programme stream, not a checklist at the end.
Practical governance guardrail: no service goes live without automated security testing in the pipeline, production grade secrets management, and standardised logging that can support audit and incident response.
Operating model and governance: what must change so microservices do not turn into chaos
Microservices are an operating model upgrade disguised as an architecture initiative.
Accountability moves from “project” to “product”
A service should have a clear owner, a lifecycle, and an SLO. Without that, on call becomes a blame game.
Platform engineering becomes a force multiplier
CircleCI’s 2024 release notes call out platform engineering as an emerging practice that helps scale effective delivery practices. In a microservices context, platform engineering is the difference between “every team builds their own pipeline” and “teams ship safely by default”.
Governance becomes lighter but more enforceable
You need fewer design review meetings and more automated controls. The governance stack that works:
- Architecture guardrails: reference architectures, approved patterns, golden paths.
- Policy as code: security and compliance controls enforced in CI/CD.
- FinOps controls: tagging, budgets, and service level cost reporting.
Anonymised example: an EU insurer moved from a quarterly release train to weekly releases by first standardising CI/CD, observability, and incident playbooks on the monolith. Only then did they carve out two domains into services. The early win was not “microservices”. The win was predictable change with measurable downtime reduction.
Implementation approach: phases, guardrails, and typical failure modes
If you decide when microservices make sense for your context, treat migration as a phased capital allocation decision.
Phase 0: Stabilise and instrument the monolith
Before extraction, define service boundaries and measure baseline KPIs:
- Lead time for change
- Deployment frequency
- Change failure rate
- Mean time to recovery
- Business KPIs: conversion, cycle time, cost per transaction, customer satisfaction
This is where many teams discover the monolith is not the issue. The issue is missing telemetry and unclear ownership.
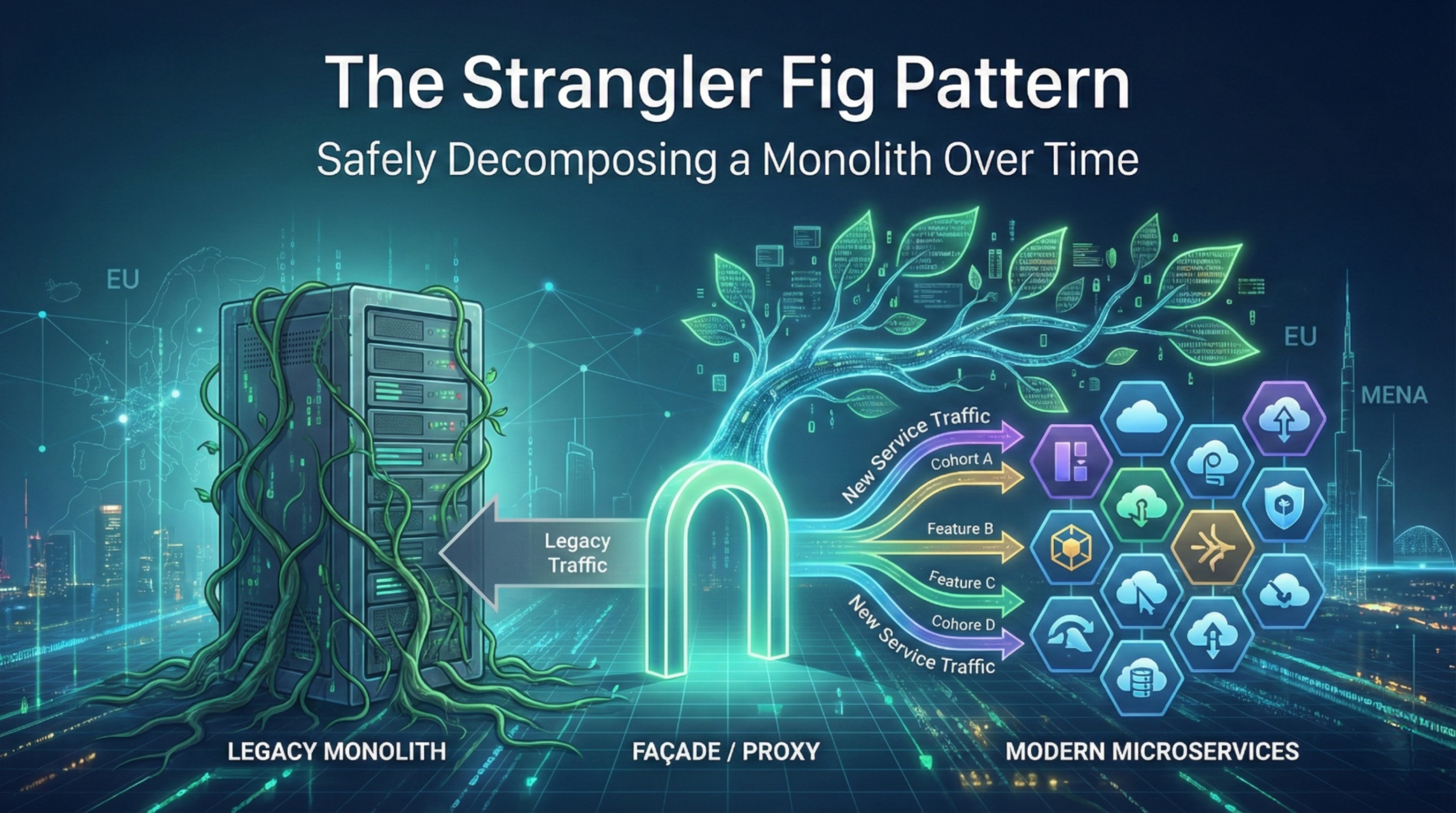
Phase 1: Carve out one high value domain
Pick a domain with clear boundaries and measurable business value. Typical candidates: notifications, document generation, payments adapters, workflow orchestration components.
Guardrails:
- Contract first APIs
- Centralised identity and access patterns
- Standardised logging, tracing, and alerting
Phase 2: Build the “paved road” and repeat
Scale by standardising:
- Service templates
- CI/CD pipelines with policy gates
- Observability standards
- Cost and tagging standards
Phase 3: Rationalise data and reduce coupling
This is the hard part. Data migration, reporting rework, and event driven consistency take time. If you skip this, you will stall.
Typical failure modes you should plan against:
- “Too many services too soon” and no platform
- Shared database persistence that blocks autonomy
- No SLO ownership, resulting in constant escalations
- Cost blowouts because environments and telemetry sprawl
- Security gaps due to inconsistent IAM and secrets handling
Anonymised example: a MENA logistics firm split into microservices to “go faster”, but kept a shared database for reporting. They gained deployment complexity without autonomy. The turnaround was to introduce bounded context ownership and move reporting to a governed analytical layer, which finally allowed independent releases.
Actionable Takeaways
- Start with the decision test. Only proceed when microservices make sense for at least three business driven reasons.
- Stabilise the monolith first. Instrumentation and ownership often unlock more value than a rewrite.
- Treat platform engineering as mandatory, not optional.
- Fund FinOps and security as part of the architecture, not as overhead.
- Define data ownership early. Shared tables kill autonomy.
- Standardise contracts and observability before scaling service count.
- Measure value realisation using delivery metrics plus business KPIs, not architecture milestones.
- Migrate in thin slices with rollback paths, not big bang replatforming.
Meet The Author
Meet The Author

Senior software engineer focused on backend systems and Android apps, delivering scalable web/mobile/cloud solutions. Leads technical direction, mentors teams, and ships high-performance services using ASP.NET Core/C#, microservices, and cloud-native infrastructure.
Senior software engineer focused on backend systems and Android apps, delivering scalable web/mobile/cloud solutions. Leads technical direction, mentors teams, and ships high-performance services using ASP.NET Core/C#, microservices, and cloud-native infrastructure.
Averroa Principal