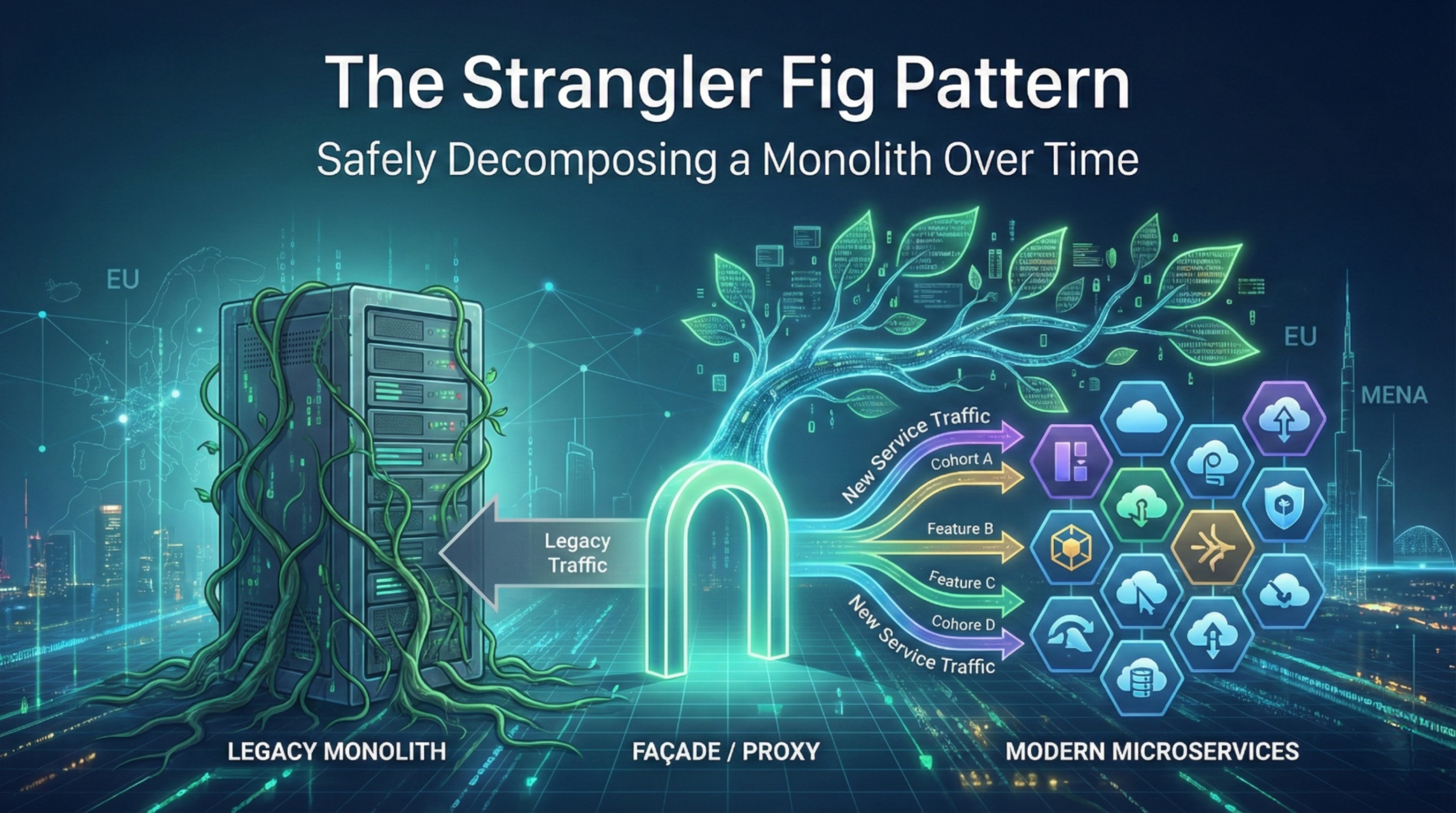
Most microservices programmes fail before the first service is extracted. The root cause is not the code. It is missing microservices prerequisites across delivery, ownership, and operational control. The market has moved to cloud native at scale, but readiness is uneven. In the CNCF Annual Survey 2024, only 38% of respondents said 80% to 100% of releases are automated, even though the organisational average automation level rose to 59.2% in 2024. That gap matters because microservices multiply release paths, environments, and failure modes.
Meanwhile, delivery expectations are rising. CircleCI’s 2024 report notes throughput is up 11% overall and 68% on production branches, and median recovery from errors is now under 60 minutes. In parallel, observability is changing shape. Grafana’s 2025 Observability Survey reports 41% use OpenTelemetry in production and 38% are investigating it.
For EU and MENA decision makers, this is a business risk question. Microservices can reduce blast radius and improve agility, but only if the operating model and DevOps foundations are strong enough to carry the load. This article lays out the prerequisites that prevent a “distributed monolith” outcome.
Microservices prerequisites: what must be true before you split code
If you want a clean microservices migration, treat it as a capability upgrade, not an architecture refactor. The microservices prerequisites sit in three places: how teams work, how software ships, and how systems are operated under pressure.
A practical way to frame this for executives is to ask three questions up front:
- Can we ship safely and repeatedly with low manual effort?
- Do teams own outcomes end to end, including on call and remediation?
- Can we observe, secure, and govern a distributed system at scale?
If any answer is “not yet”, microservices can still be on the roadmap, but your near term work should be foundation, not decomposition.
Business impact and risk
Microservices increase your operational surface area: more deployable units, more identities, more integrations, and more cost allocation points. That can pay back through speed and resilience, but it also increases the probability of partial failure. Security exposure also becomes more distributed. IBM’s Cost of a Data Breach Report 2024 puts the global average cost of a breach at USD 4.88 million. That is the risk floor you are building above.
A strong opinion, based on repeated failure patterns: if your current monolith releases are fragile, microservices will not make them safer. They will make fragility faster and more expensive.
Organisational prerequisites: ownership, Conway’s Law, and governance that scales
Microservices are an organisational design decision. Conway’s Law is not a slogan. It is a forecasting tool: your architecture will mirror your communication structure. If your organisation is still optimised for functional silos, microservices will look like a maze of handoffs and escalations.
Team ownership is a prerequisite, not an aspiration
Each service needs a clear owner with authority over backlog, roadmap, and run. The minimum ownership model that works:
- A named product owner or business sponsor per domain
- A technical owner accountable for service health and delivery outcomes
- An on call arrangement that is realistic for the service’s criticality
- A shared platform or enablement function that provides standards and guardrails
DORA’s 2024 research, based on responses from more than 39,000 professionals, highlights platform engineering promises and challenges and points to the need for stable priorities and organisational discipline. This is the governance message executives tend to underfund.
Governance must move from meetings to guardrails
Microservices programmes fail when governance stays manual and centralised. That produces either gridlock or shadow IT. Governance that scales is governance as code plus a small number of explicit exceptions.
A governance baseline that supports microservices prerequisites:
- Reference architectures for common service types
- API standards and versioning rules
- Security controls enforced in CI/CD, not in slide decks
- Logging, metrics, and tracing standards that allow cross service incident triage
- Cost tagging standards that enable service level unit economics
Operating model changes to make explicit
If you adopt microservices, you are also changing how work is funded and planned. Budget lines shift from projects to products and platforms. Decision rights shift from central committees to team level execution within guardrails. Metrics shift from feature delivery to service outcomes.
Anonymised example: a regulated EU enterprise tried microservices while keeping a central architecture approval board for every change. Release cadence slowed, teams bypassed standards, and the incident rate climbed. The programme recovered only after introducing service templates, automated policy gates, and clear domain ownership with a lightweight exception process.
DevOps prerequisites: CI/CD, automation, and security discipline
Most migrations fail here because teams underestimate the compounding effect of service count. Ten services do not create ten times the effort. They can create an order of magnitude more coordination unless you standardise delivery.
CI/CD maturity is a leading indicator of readiness
CNCF Annual Survey 2024 data shows release automation is improving, but it is not universal. Only 38% reported 80% to 100% automated releases, and the organisational average automation level was 59.2% in 2024. In the same report, CI/CD is listed among the top challenges for using and deploying containers, alongside monitoring, logging, security, and cultural changes.
If your automation is below the 80% threshold, microservices prerequisites should focus on release pipelines before service extraction.
Delivery performance and recovery need to be engineered, not hoped for
CircleCI’s 2024 State of Software Delivery reports throughput is up 11% across all branches and 68% on production branches. It also notes that median recovery from errors is under 60 minutes. The implication is not that every enterprise should copy those numbers. The implication is that the benchmark for “acceptable” has shifted. Leadership will expect faster recovery and tighter feedback loops, especially in customer facing workflow platforms.
Microservices prerequisites here are concrete:
- Trunk based development or a disciplined branching model
- Automated tests that are meaningful, not just numerous
- Progressive delivery patterns such as canary releases and feature flags
- Fast rollback and forward fix capability
- Dependency and vulnerability management that is continuous
DevSecOps is not optional in a distributed estate
Service count increases the number of places secrets can leak and policies can drift. GitLab’s 2024 Global DevSecOps Survey highlights a strong desire to streamline toolchains, with 74% of AI users wanting consolidation to reduce complexity and context switching. The operational implication is straightforward: fewer inconsistent tools and more standard pipelines generally improves control and auditability.
For EU and cross border firms, the direction of travel is also clear. NIS2 raises baseline expectations for cyber risk management and reporting, with a transposition deadline of 17 October 2024. Even where you are not formally in scope, customers and regulators increasingly expect similar capability.
Architectural prerequisites: boundaries, integration, data, and observability
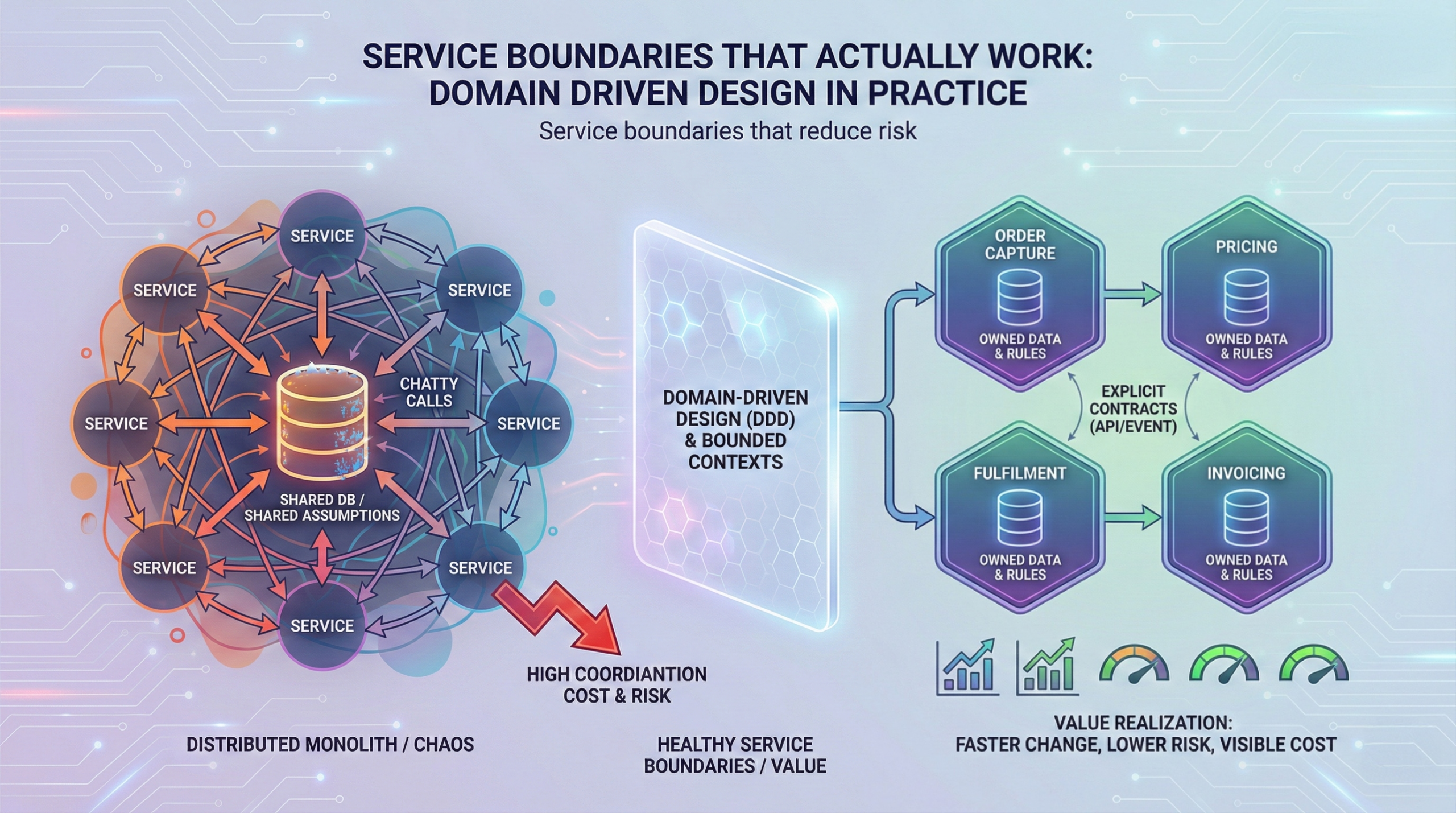
A microservices target architecture without boundary discipline becomes integration debt. The architectural microservices prerequisites are about reducing coupling before you distribute it.
Domain boundaries and a managed integration surface
Before writing services, define bounded contexts and integration contracts. Otherwise, teams extract services that still require constant coordination.
A practical boundary checklist:
- A domain has a stable business vocabulary and ownership
- Data ownership is clear, including PII responsibilities
- The domain can evolve without forcing synchronous changes elsewhere
- Dependencies are explicit and versioned
Data ownership is where migrations stall
Microservices rarely fail because engineers cannot build services. They fail because data remains shared and reporting requirements remain centralised.
Microservices prerequisites for data:
- A clear “system of record” per domain
- A strategy for cross domain reads, often via APIs or a governed analytical layer
- A plan for eventual consistency and reconciliation
- A migration strategy for reporting that does not require shared transactional tables
Observability is an executive control system
In a monolith, partial failures can be found with coarse logs and intuition. In microservices, you need traceability across calls and queues.
Grafana’s 2025 Observability Survey reports 67% use Prometheus in production in some capacity. It also reports OpenTelemetry production usage at 41%, with 38% investigating it. The implication is that observability is standardising around shared components, but adoption is still in flight. If your estate lacks consistent tracing and service level telemetry, microservices will increase mean time to understand and mean time to recover.
Microservices prerequisites for observability:
- Standard logs, metrics, and traces across all services
- Correlation IDs and trace context propagation
- Service level dashboards tied to SLOs
- Alerting that is actionable, not noisy
- Runbooks and incident playbooks linked to telemetry
Anonymised example: a MENA logistics platform extracted services quickly but did not standardise tracing. Incident resolution regressed because teams could not follow requests across five services and two queues. The fix was not more engineers. It was standard instrumentation, a shared telemetry pipeline, and clear SLO ownership.
Implementation approach: a readiness backlog before any migration
A good migration plan treats microservices prerequisites as deliverables with owners, budgets, and KPIs. Below is an execution oriented phased approach that leaders can govern.
Phase 0: Readiness assessment and baseline KPIs
Deliverables:
- Service candidates and domain map
- Current DORA style metrics baseline: lead time, deployment frequency, change failure rate, recovery time
- Observability baseline: percentage of services with standard logs, metrics, traces
- Security baseline: percentage of repos with secrets scanning and dependency scanning
- Cost baseline: tagged spend coverage and environment counts
Guardrails:
- No service extraction without a baseline and a rollback plan
- No production release without standard telemetry
Typical failure mode: teams start coding services with no baseline, then cannot prove value or diagnose regressions.
Phase 1: Standard delivery pipeline and policy gates
Deliverables:
- Golden path pipeline template
- Automated testing gates, SAST, dependency scanning, secrets scanning
- Environment strategy that limits sprawl
- A documented release policy with exceptions
KPIs:
- Percentage of releases that are automated
- Mean pipeline duration and rework rate
- Change failure rate trend
Use CNCF automation benchmarks as directional targets. The point is to move toward high automation before multiplying services.
Phase 2: Observability and SLO operating model
Deliverables:
- Standard instrumentation library or configuration
- SLOs for critical services and error budget policies
- Incident management runbooks
KPIs:
- Coverage: services with traces and dashboards
- MTTR trend and incident recurrence rate
Phase 3: Ownership and platform enablement
Deliverables:
- Team level ownership model with on call design
- Platform function or enablement squad charter
- Governance as code and architecture standards
Typical failure mode: a “microservices factory” produces services faster than the organisation can operate them.
Phase 4: Extract one service that pays for itself
Pick a domain with clear ownership and a measurable business outcome, such as a workflow engine component, document processing, or notification services.
KPIs to prove value realisation:
- Lead time reduction for that domain
- Incident blast radius reduction
- Cost per transaction or per workflow step
- Audit readiness improvements
This approach keeps decision makers in control of risk and ensures microservices prerequisites are funded and verified before scale out.
Actionable Takeaways
- Treat microservices prerequisites as a funded programme, not an architectural preference.
- Make team ownership explicit before service extraction, including on call and SLO accountability.
- Shift governance from central approvals to automated guardrails in CI/CD.
- Raise release automation toward 80% plus before multiplying deployable units, using industry benchmarks as direction.
- Standardise observability across logs, metrics, and traces, since incident triage is harder in distributed systems.
- Define domain boundaries and data ownership early, otherwise you will recreate coupling across APIs and shared tables.
- Embed security into pipelines and simplify toolchains to reduce drift and audit gaps.
- Use KPIs that connect delivery to business outcomes, not service counts.
References
- CNCF Annual Survey 2024, “Cloud Native 2024: Approaching a Decade of Code, Cloud, and Change” published April 2025, metrics on automated releases and GitOps adoption.
- CircleCI, “The 2024 State of Software Delivery” published 2024, metrics on throughput and recovery time.
- Grafana Labs, “Observability Survey Report 2025” published 2025, statistics on Prometheus and OpenTelemetry adoption.
- DORA Research 2024, “Accelerate State of DevOps Report 2024” published October 2024, survey size and platform engineering focus.
- IBM, “Cost of a Data Breach Report 2024” published July 2024, global average breach cost.
- GitLab, “2024 Global DevSecOps Survey” published June 2024, toolchain consolidation preference statistic.
- Linux Foundation Research, CNCF survey notes on container deployment challenges including CI/CD, monitoring, logging, and security.
Most microservices programmes fail before the first service is extracted. The root cause is not the code. It is missing microservices prerequisites across delivery, ownership, and operational control. The market has moved to cloud native at scale, but readiness is uneven. In the CNCF Annual Survey 2024, only 38% of respondents said 80% to 100% of releases are automated, even though the organisational average automation level rose to 59.2% in 2024. That gap matters because microservices multiply release paths, environments, and failure modes.
Meanwhile, delivery expectations are rising. CircleCI’s 2024 report notes throughput is up 11% overall and 68% on production branches, and median recovery from errors is now under 60 minutes. In parallel, observability is changing shape. Grafana’s 2025 Observability Survey reports 41% use OpenTelemetry in production and 38% are investigating it.
For EU and MENA decision makers, this is a business risk question. Microservices can reduce blast radius and improve agility, but only if the operating model and DevOps foundations are strong enough to carry the load. This article lays out the prerequisites that prevent a “distributed monolith” outcome.
Microservices prerequisites: what must be true before you split code
If you want a clean microservices migration, treat it as a capability upgrade, not an architecture refactor. The microservices prerequisites sit in three places: how teams work, how software ships, and how systems are operated under pressure.
A practical way to frame this for executives is to ask three questions up front:
- Can we ship safely and repeatedly with low manual effort?
- Do teams own outcomes end to end, including on call and remediation?
- Can we observe, secure, and govern a distributed system at scale?
If any answer is “not yet”, microservices can still be on the roadmap, but your near term work should be foundation, not decomposition.
Business impact and risk
Microservices increase your operational surface area: more deployable units, more identities, more integrations, and more cost allocation points. That can pay back through speed and resilience, but it also increases the probability of partial failure. Security exposure also becomes more distributed. IBM’s Cost of a Data Breach Report 2024 puts the global average cost of a breach at USD 4.88 million. That is the risk floor you are building above.
A strong opinion, based on repeated failure patterns: if your current monolith releases are fragile, microservices will not make them safer. They will make fragility faster and more expensive.
Organisational prerequisites: ownership, Conway’s Law, and governance that scales
Microservices are an organisational design decision. Conway’s Law is not a slogan. It is a forecasting tool: your architecture will mirror your communication structure. If your organisation is still optimised for functional silos, microservices will look like a maze of handoffs and escalations.
Team ownership is a prerequisite, not an aspiration
Each service needs a clear owner with authority over backlog, roadmap, and run. The minimum ownership model that works:
- A named product owner or business sponsor per domain
- A technical owner accountable for service health and delivery outcomes
- An on call arrangement that is realistic for the service’s criticality
- A shared platform or enablement function that provides standards and guardrails
DORA’s 2024 research, based on responses from more than 39,000 professionals, highlights platform engineering promises and challenges and points to the need for stable priorities and organisational discipline. This is the governance message executives tend to underfund.
Governance must move from meetings to guardrails
Microservices programmes fail when governance stays manual and centralised. That produces either gridlock or shadow IT. Governance that scales is governance as code plus a small number of explicit exceptions.
A governance baseline that supports microservices prerequisites:
- Reference architectures for common service types
- API standards and versioning rules
- Security controls enforced in CI/CD, not in slide decks
- Logging, metrics, and tracing standards that allow cross service incident triage
- Cost tagging standards that enable service level unit economics
Operating model changes to make explicit
If you adopt microservices, you are also changing how work is funded and planned. Budget lines shift from projects to products and platforms. Decision rights shift from central committees to team level execution within guardrails. Metrics shift from feature delivery to service outcomes.
Anonymised example: a regulated EU enterprise tried microservices while keeping a central architecture approval board for every change. Release cadence slowed, teams bypassed standards, and the incident rate climbed. The programme recovered only after introducing service templates, automated policy gates, and clear domain ownership with a lightweight exception process.
DevOps prerequisites: CI/CD, automation, and security discipline
Most migrations fail here because teams underestimate the compounding effect of service count. Ten services do not create ten times the effort. They can create an order of magnitude more coordination unless you standardise delivery.
CI/CD maturity is a leading indicator of readiness
CNCF Annual Survey 2024 data shows release automation is improving, but it is not universal. Only 38% reported 80% to 100% automated releases, and the organisational average automation level was 59.2% in 2024. In the same report, CI/CD is listed among the top challenges for using and deploying containers, alongside monitoring, logging, security, and cultural changes.
If your automation is below the 80% threshold, microservices prerequisites should focus on release pipelines before service extraction.
Delivery performance and recovery need to be engineered, not hoped for
CircleCI’s 2024 State of Software Delivery reports throughput is up 11% across all branches and 68% on production branches. It also notes that median recovery from errors is under 60 minutes. The implication is not that every enterprise should copy those numbers. The implication is that the benchmark for “acceptable” has shifted. Leadership will expect faster recovery and tighter feedback loops, especially in customer facing workflow platforms.
Microservices prerequisites here are concrete:
- Trunk based development or a disciplined branching model
- Automated tests that are meaningful, not just numerous
- Progressive delivery patterns such as canary releases and feature flags
- Fast rollback and forward fix capability
- Dependency and vulnerability management that is continuous
DevSecOps is not optional in a distributed estate
Service count increases the number of places secrets can leak and policies can drift. GitLab’s 2024 Global DevSecOps Survey highlights a strong desire to streamline toolchains, with 74% of AI users wanting consolidation to reduce complexity and context switching. The operational implication is straightforward: fewer inconsistent tools and more standard pipelines generally improves control and auditability.
For EU and cross border firms, the direction of travel is also clear. NIS2 raises baseline expectations for cyber risk management and reporting, with a transposition deadline of 17 October 2024. Even where you are not formally in scope, customers and regulators increasingly expect similar capability.
Architectural prerequisites: boundaries, integration, data, and observability
A microservices target architecture without boundary discipline becomes integration debt. The architectural microservices prerequisites are about reducing coupling before you distribute it.
Domain boundaries and a managed integration surface
Before writing services, define bounded contexts and integration contracts. Otherwise, teams extract services that still require constant coordination.
A practical boundary checklist:
- A domain has a stable business vocabulary and ownership
- Data ownership is clear, including PII responsibilities
- The domain can evolve without forcing synchronous changes elsewhere
- Dependencies are explicit and versioned
Data ownership is where migrations stall
Microservices rarely fail because engineers cannot build services. They fail because data remains shared and reporting requirements remain centralised.
Microservices prerequisites for data:
- A clear “system of record” per domain
- A strategy for cross domain reads, often via APIs or a governed analytical layer
- A plan for eventual consistency and reconciliation
- A migration strategy for reporting that does not require shared transactional tables
Observability is an executive control system
In a monolith, partial failures can be found with coarse logs and intuition. In microservices, you need traceability across calls and queues.
Grafana’s 2025 Observability Survey reports 67% use Prometheus in production in some capacity. It also reports OpenTelemetry production usage at 41%, with 38% investigating it. The implication is that observability is standardising around shared components, but adoption is still in flight. If your estate lacks consistent tracing and service level telemetry, microservices will increase mean time to understand and mean time to recover.
Microservices prerequisites for observability:
- Standard logs, metrics, and traces across all services
- Correlation IDs and trace context propagation
- Service level dashboards tied to SLOs
- Alerting that is actionable, not noisy
- Runbooks and incident playbooks linked to telemetry
Anonymised example: a MENA logistics platform extracted services quickly but did not standardise tracing. Incident resolution regressed because teams could not follow requests across five services and two queues. The fix was not more engineers. It was standard instrumentation, a shared telemetry pipeline, and clear SLO ownership.
Implementation approach: a readiness backlog before any migration
A good migration plan treats microservices prerequisites as deliverables with owners, budgets, and KPIs. Below is an execution oriented phased approach that leaders can govern.
Phase 0: Readiness assessment and baseline KPIs
Deliverables:
- Service candidates and domain map
- Current DORA style metrics baseline: lead time, deployment frequency, change failure rate, recovery time
- Observability baseline: percentage of services with standard logs, metrics, traces
- Security baseline: percentage of repos with secrets scanning and dependency scanning
- Cost baseline: tagged spend coverage and environment counts
Guardrails:
- No service extraction without a baseline and a rollback plan
- No production release without standard telemetry
Typical failure mode: teams start coding services with no baseline, then cannot prove value or diagnose regressions.
Phase 1: Standard delivery pipeline and policy gates
Deliverables:
- Golden path pipeline template
- Automated testing gates, SAST, dependency scanning, secrets scanning
- Environment strategy that limits sprawl
- A documented release policy with exceptions
KPIs:
- Percentage of releases that are automated
- Mean pipeline duration and rework rate
- Change failure rate trend
Use CNCF automation benchmarks as directional targets. The point is to move toward high automation before multiplying services.
Phase 2: Observability and SLO operating model
Deliverables:
- Standard instrumentation library or configuration
- SLOs for critical services and error budget policies
- Incident management runbooks
KPIs:
- Coverage: services with traces and dashboards
- MTTR trend and incident recurrence rate
Phase 3: Ownership and platform enablement
Deliverables:
- Team level ownership model with on call design
- Platform function or enablement squad charter
- Governance as code and architecture standards
Typical failure mode: a “microservices factory” produces services faster than the organisation can operate them.
Phase 4: Extract one service that pays for itself
Pick a domain with clear ownership and a measurable business outcome, such as a workflow engine component, document processing, or notification services.
KPIs to prove value realisation:
- Lead time reduction for that domain
- Incident blast radius reduction
- Cost per transaction or per workflow step
- Audit readiness improvements
This approach keeps decision makers in control of risk and ensures microservices prerequisites are funded and verified before scale out.
Actionable Takeaways
- Treat microservices prerequisites as a funded programme, not an architectural preference.
- Make team ownership explicit before service extraction, including on call and SLO accountability.
- Shift governance from central approvals to automated guardrails in CI/CD.
- Raise release automation toward 80% plus before multiplying deployable units, using industry benchmarks as direction.
- Standardise observability across logs, metrics, and traces, since incident triage is harder in distributed systems.
- Define domain boundaries and data ownership early, otherwise you will recreate coupling across APIs and shared tables.
- Embed security into pipelines and simplify toolchains to reduce drift and audit gaps.
- Use KPIs that connect delivery to business outcomes, not service counts.
References
- CNCF Annual Survey 2024, “Cloud Native 2024: Approaching a Decade of Code, Cloud, and Change” published April 2025, metrics on automated releases and GitOps adoption.
- CircleCI, “The 2024 State of Software Delivery” published 2024, metrics on throughput and recovery time.
- Grafana Labs, “Observability Survey Report 2025” published 2025, statistics on Prometheus and OpenTelemetry adoption.
- DORA Research 2024, “Accelerate State of DevOps Report 2024” published October 2024, survey size and platform engineering focus.
- IBM, “Cost of a Data Breach Report 2024” published July 2024, global average breach cost.
- GitLab, “2024 Global DevSecOps Survey” published June 2024, toolchain consolidation preference statistic.
- Linux Foundation Research, CNCF survey notes on container deployment challenges including CI/CD, monitoring, logging, and security.
Meet The Author
Meet The Author

Senior software engineer focused on backend systems and Android apps, delivering scalable web/mobile/cloud solutions. Leads technical direction, mentors teams, and ships high-performance services using ASP.NET Core/C#, microservices, and cloud-native infrastructure.
Senior software engineer focused on backend systems and Android apps, delivering scalable web/mobile/cloud solutions. Leads technical direction, mentors teams, and ships high-performance services using ASP.NET Core/C#, microservices, and cloud-native infrastructure.
Averroa Principal
Table of content
- Microservices prerequisites: what must be true before you split code
- Business impact and risk
- Organisational prerequisites: ownership, Conway’s Law, and governance that scales
- DevOps prerequisites: CI/CD, automation, and security discipline
- Architectural prerequisites: boundaries, integration, data, and observability
- Implementation approach: a readiness backlog before any migration
- Actionable Takeaways
- References