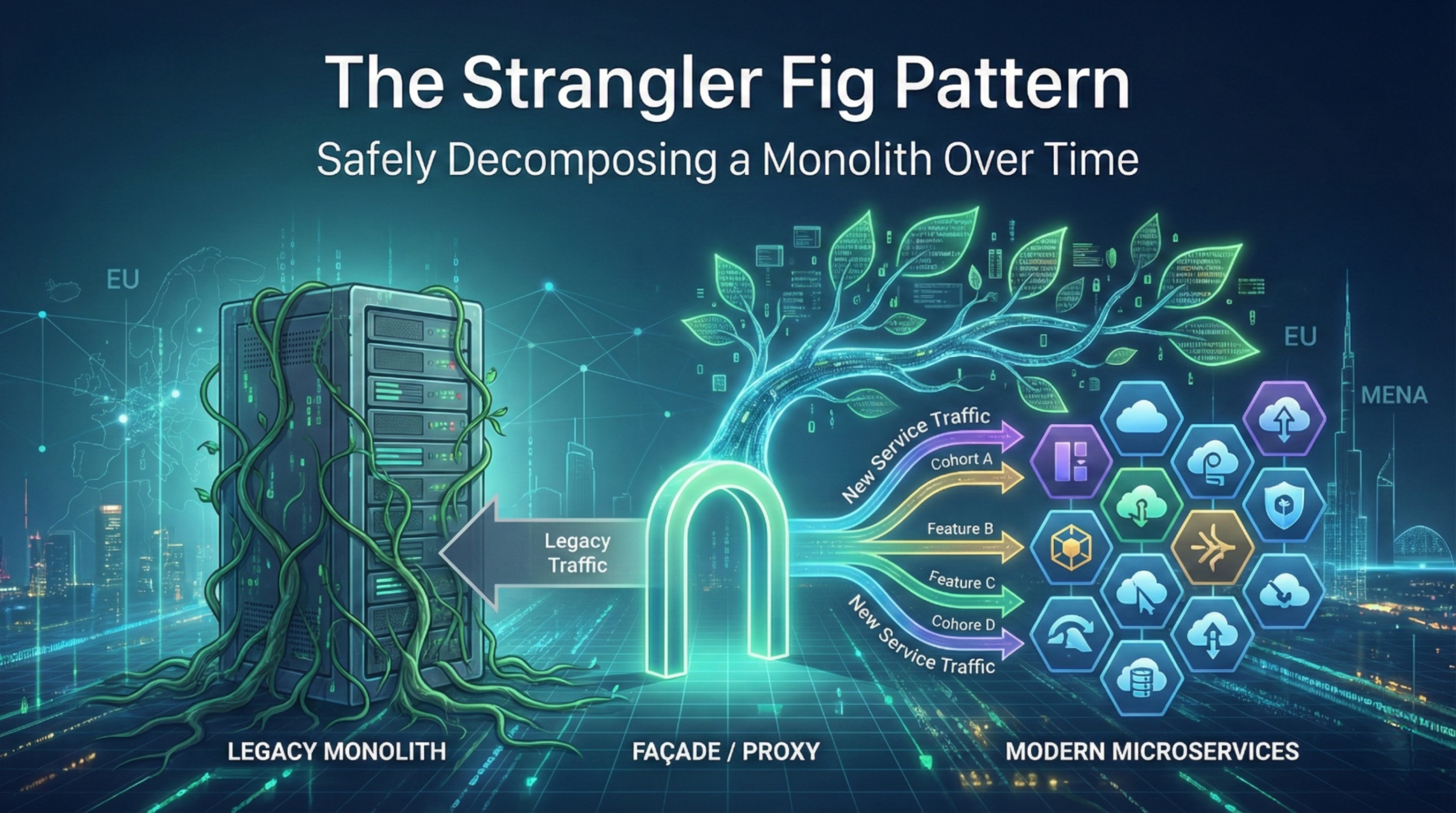
Life After Migration: How to Avoid Service Sprawl When Microservices Become Legacy
Most organisations worry about the migration itself. The quieter risk arrives 12 to 24 months later: service sprawl. Teams keep shipping services, the catalogue grows, ownership blurs, and the platform becomes harder to change than the monolith it replaced. That is how microservices become the new legacy.
The timing is not theoretical. Platform engineering is accelerating precisely because complexity has outgrown informal practices. Gartner forecasts that by 2026, 80% of large software engineering organisations will establish platform engineering teams, up from 45% in 2022. DORA reports that by 2025, 90% of organisations use an internal developer platform and 76% have dedicated platform teams. This is the market acknowledging that “let every team build their own path” does not scale.
Cost pressure makes the problem sharper. Flexera reports 84% of respondents say managing cloud spend is the top cloud challenge, and cloud spend is expected to rise 28% in the coming year. In other words, you cannot afford uncontrolled growth in services, environments, telemetry, and duplicated data.
This final article is about the long game: how to prevent service sprawl, how platform teams and internal developer experience keep delivery fast, and which KPIs prove that microservices are still earning their keep.
Service sprawl is the new legacy: what it looks like and why it happens
Service sprawl is not “too many services”. It is unmanaged growth in services, dependencies, and operational obligations relative to the organisation’s ability to govern them.
In practice, service sprawl shows up as five symptoms that leaders can recognise without reading code.
- Ownership dilution
A service exists, but no one feels accountable for its reliability, its cost, or its roadmap. On call rotates without context. Incidents become escalations. - Dependency fog
No one can answer “what breaks if we change this” without tribal knowledge. Tracing exists, but dependency mapping is incomplete. - Inconsistent ways of working
Different teams use different build systems, deployment patterns, secrets handling, and logging formats. Standardisation happens in meetings, not in paved roads. - Portfolio drift
Services overlap. Business rules are duplicated. Data is copied into multiple stores. Reconciliation becomes operational debt. - Cost surfaces multiply
Environments remain alive “just in case”. Observability retention grows by default. Data pipelines and caches duplicate.
The result is predictable: microservices become a legacy estate, just distributed.
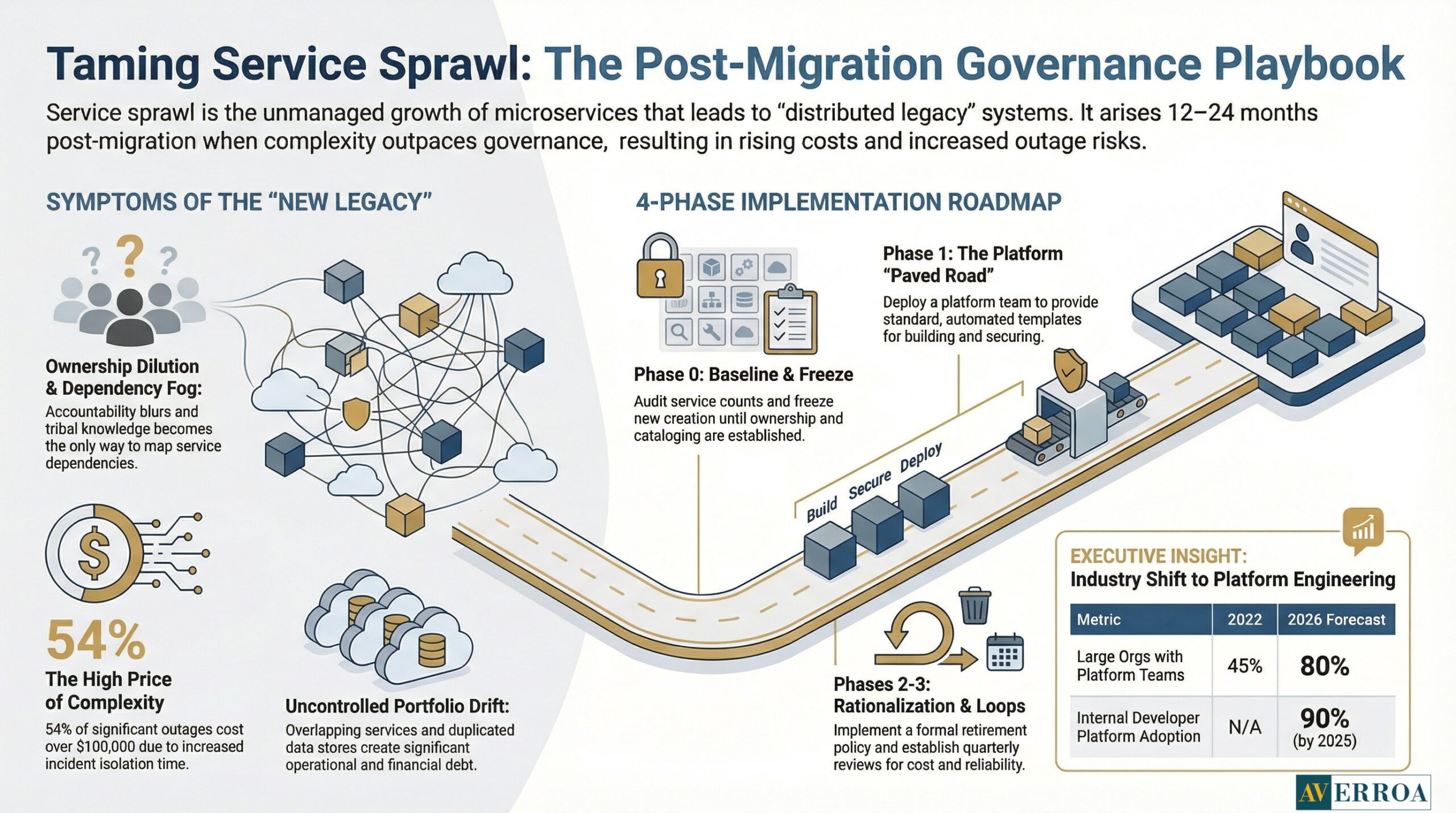
Business impact and risk
Service sprawl increases outage probability and recovery time because there are more moving parts and weaker ownership. Outage economics are not forgiving. Uptime Institute’s Annual Outage Analysis 2024 executive summary reports that 54% of respondents said their most recent significant outage cost more than $100,000, and 16% said it cost more than $1 million. Service sprawl does not create every outage, but it reliably increases incident complexity and the time required to isolate root causes.
Cost is the second pressure point. Flexera reports 84% of respondents see cloud spend management as the top cloud challenge, with expected cloud spend growth of 28% in the coming year. When service sprawl increases telemetry, data duplication, and parallel environments, it pushes directly into that cost challenge.
What changes in operating model and governance
In a monolith, architecture governance can be centralised. In microservices, central governance becomes a bottleneck unless it is converted into automation and clear guardrails.
Service sprawl is often the outcome of an “independent teams at all costs” interpretation. Independence needs constraints. That is a traditional enterprise lesson that still applies: freedom without standards becomes chaos. Modern practice simply moves standards into platforms, templates, and policy controls.
Architecture and integration implications
Service sprawl grows when interfaces are treated as an afterthought. Every service creates more contracts and versioning pressure. The cure is not heavier review boards. The cure is explicit lifecycle management: service catalogues, contract policies, and deprecation paths that are visible and enforced.
Anonymised example, EU
A regulated enterprise migrated core case management into services and hit service sprawl by year two. The service count grew, but no consistent ownership model existed for shared libraries, queues, and integration adapters. The organisation stabilised by creating a service catalogue with owners, defining “critical journey” owners across services, and enforcing standard observability and security templates. The key shift was governance. It became executable, not advisory.
Platform teams are the control plane for service sprawl
Platform engineering exists because service sprawl is a scaling limit. The evidence is increasingly explicit.
Gartner forecasts that by 2026, 80% of large software engineering organisations will establish platform engineering teams, up from 45% in 2022. DORA goes further, reporting that by 2025 adoption of internal developer platforms is 90%, with 76% establishing dedicated platform teams. The implication is direct: enterprises are normalising the idea that developer enablement is a product, and that product must be owned.
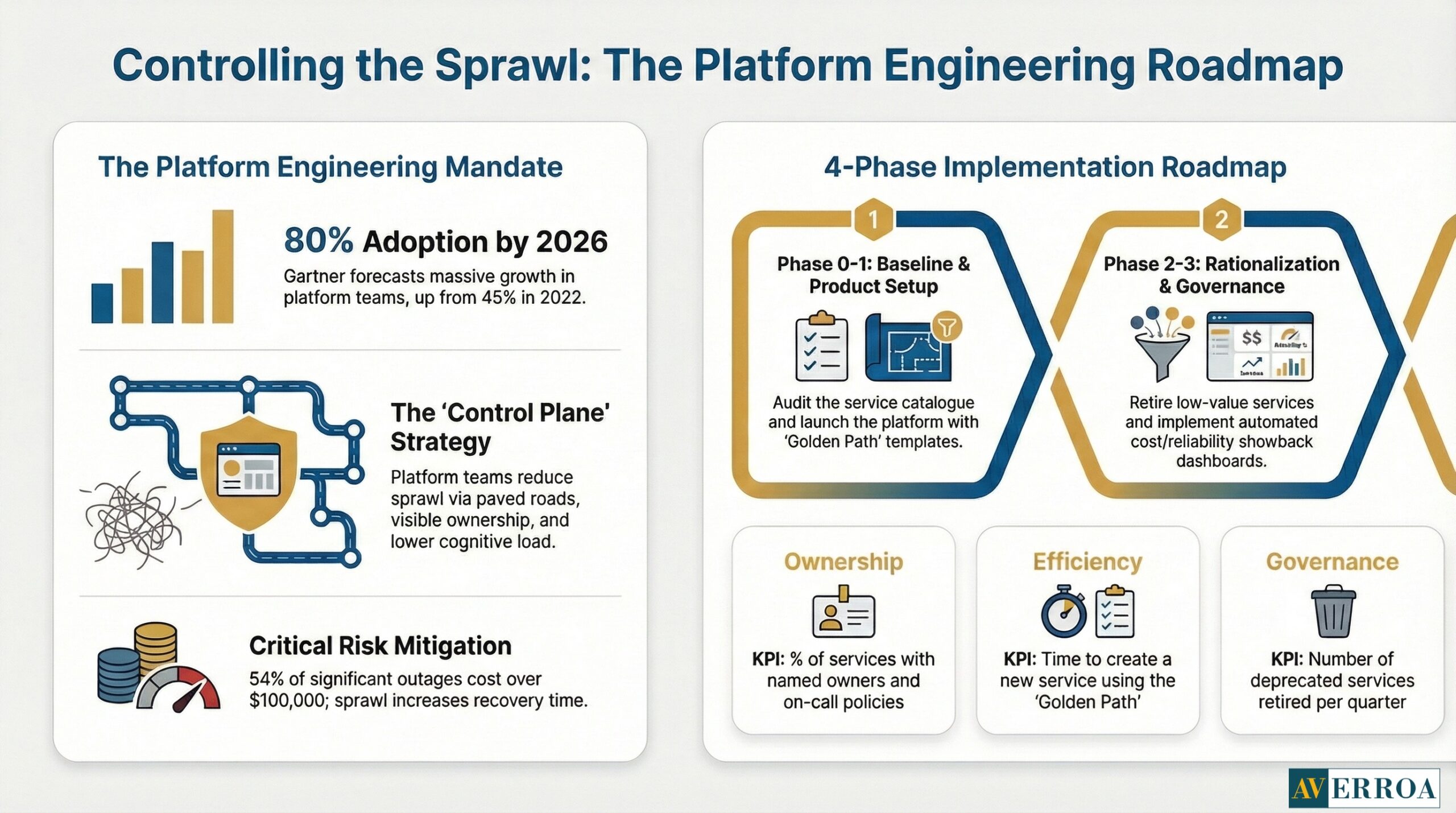
Platform teams prevent service sprawl by doing three things:
1) Providing paved roads
A paved road is a standard way to build, deploy, secure, and observe services. It makes the right thing easy, and the risky thing harder. This is how you scale governance without scaling bureaucracy.
2) Making ownership visible
A platform can enforce ownership metadata. Services without an owner cannot pass certain gates. That is a simple rule that reduces service sprawl quickly.
3) Reducing cognitive load with internal developer experience
Service sprawl is often a cognitive load problem. Developers spend time navigating tooling and policy rather than shipping value.
Internal developer portals and catalogues address this. One market signal is the 2024 internal developer portal report by Port, which states that almost 85% of surveyed companies have either started implementing a portal (50%) or plan to do so in the next year (35%). The implication is not that portals are mandatory. The implication is that discoverability and standards are becoming essential as estates grow.
Backstage is a concrete ecosystem reference point. CNCF’s own blog notes Backstage has more than 3,000 adopters and 2,000 contributors worldwide, and as of October 2024 has over 270 public adopters. This matters because it signals that service catalogues and portals are no longer niche. They are becoming standard tooling in the fight against service sprawl.
Operating model and governance changes
Platform teams need a product posture. They require a roadmap, SLAs, adoption metrics, and explicit decision rights. Otherwise they become a ticket queue, and service sprawl continues.
A useful reality check comes from the State of Platform Engineering Vol 4 report, which found 55.9% of companies operate more than one platform. The implication is that “one platform to rule them all” is not the goal. The goal is controlled plurality with consistent standards. Multiple platforms can be rational if they are intentionally designed and governed.
Anonymised example, MENA
A fast-growing enterprise built multiple microservice teams with high autonomy. Service sprawl followed: inconsistent pipelines, duplicated authentication adapters, and uneven logging. A platform team introduced golden path templates and an internal portal that made service ownership and runbooks discoverable. Service sprawl did not disappear, but it stopped accelerating because teams defaulted to standard patterns.
Architecture hygiene that prevents service sprawl: lifecycle, standards, and limits
Service sprawl is ultimately a lifecycle management problem. The architecture needs constraints that make growth sustainable.
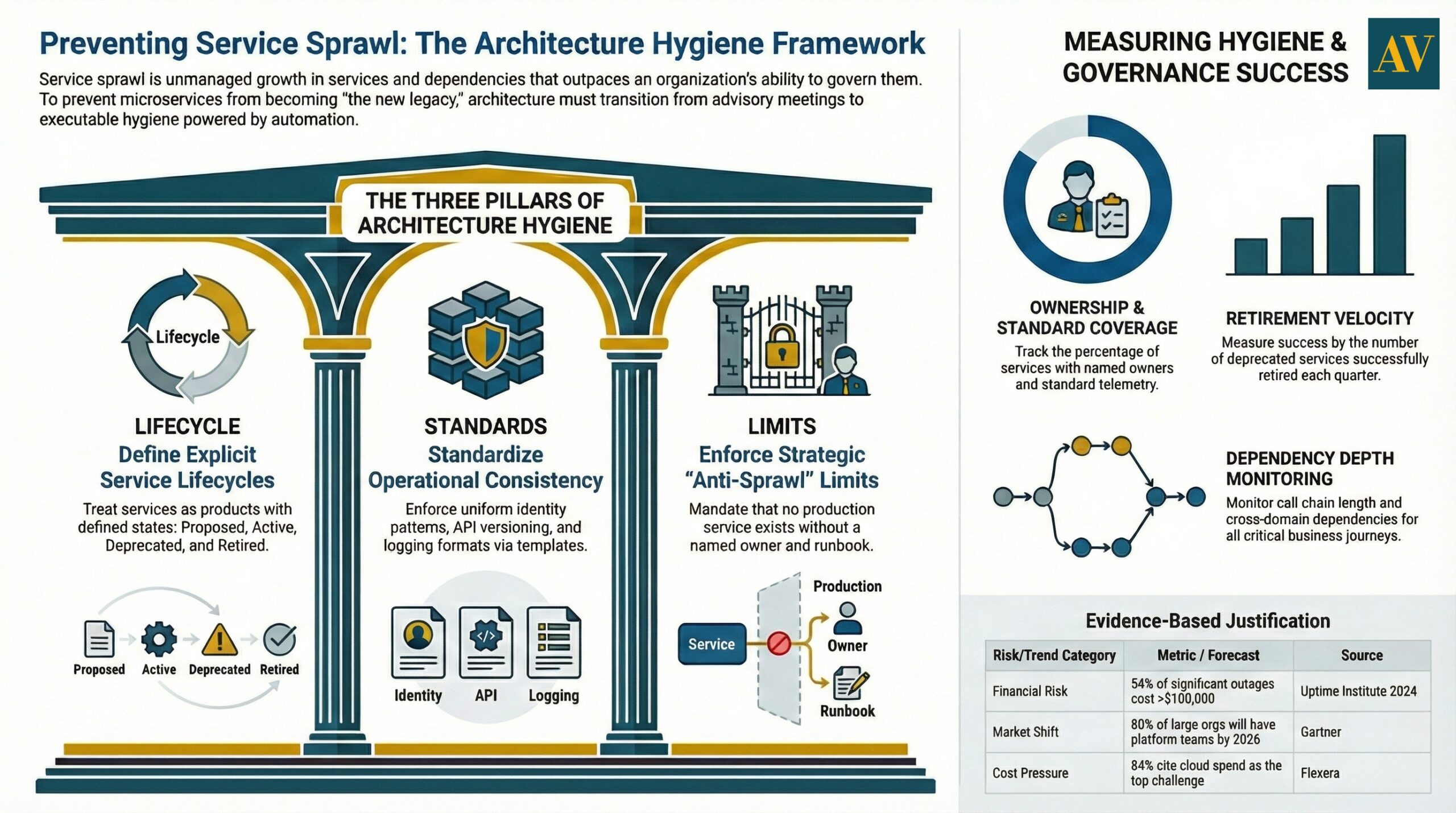
Set explicit service lifecycle states
Treat services like products. Define states such as: proposed, active, deprecated, retired. Enforce these in the catalogue and CI policies.
Standardise what must be consistent
Standards that matter for service sprawl control:
- Identity patterns for service-to-service access
- Logging, metrics, and tracing conventions
- API versioning and deprecation policy
- Data ownership rules and replication constraints
- Incident runbooks and escalation paths
These standards should be delivered as templates and checks. Meeting-based governance does not scale.
Put limits where it hurts, not where it is comfortable
A practical anti-sprawl rule set:
- No production service without an owner, on-call policy, and runbook.
- No new service without a cost attribution tag and a unit cost hypothesis.
- No public API without versioning and deprecation dates.
- No shared database writes across services.
- No long-lived environments without an expiry policy.
Architecture and integration implications
Service sprawl tends to increase coupling through accidental dependency chains. A catalogue helps map dependencies, but you also need integration discipline. Events and APIs should reduce coupling, not multiply it. This is where consistent schema governance and contract testing pay back.
A market-level context for why discipline matters: CNCF’s Annual Cloud Native Survey (Jan 20, 2026) reports that 82% of container users are running Kubernetes. Kubernetes ubiquity makes it easy to create new deployable units. That is positive. It also makes it easy to create ungoverned sprawl. The differentiator becomes the platform and governance layer above it.
Implementation approach: the post-migration programme that keeps value compounding
Most organisations treat migration as a programme. They should treat post-migration as a programme too. Service sprawl is the reason.
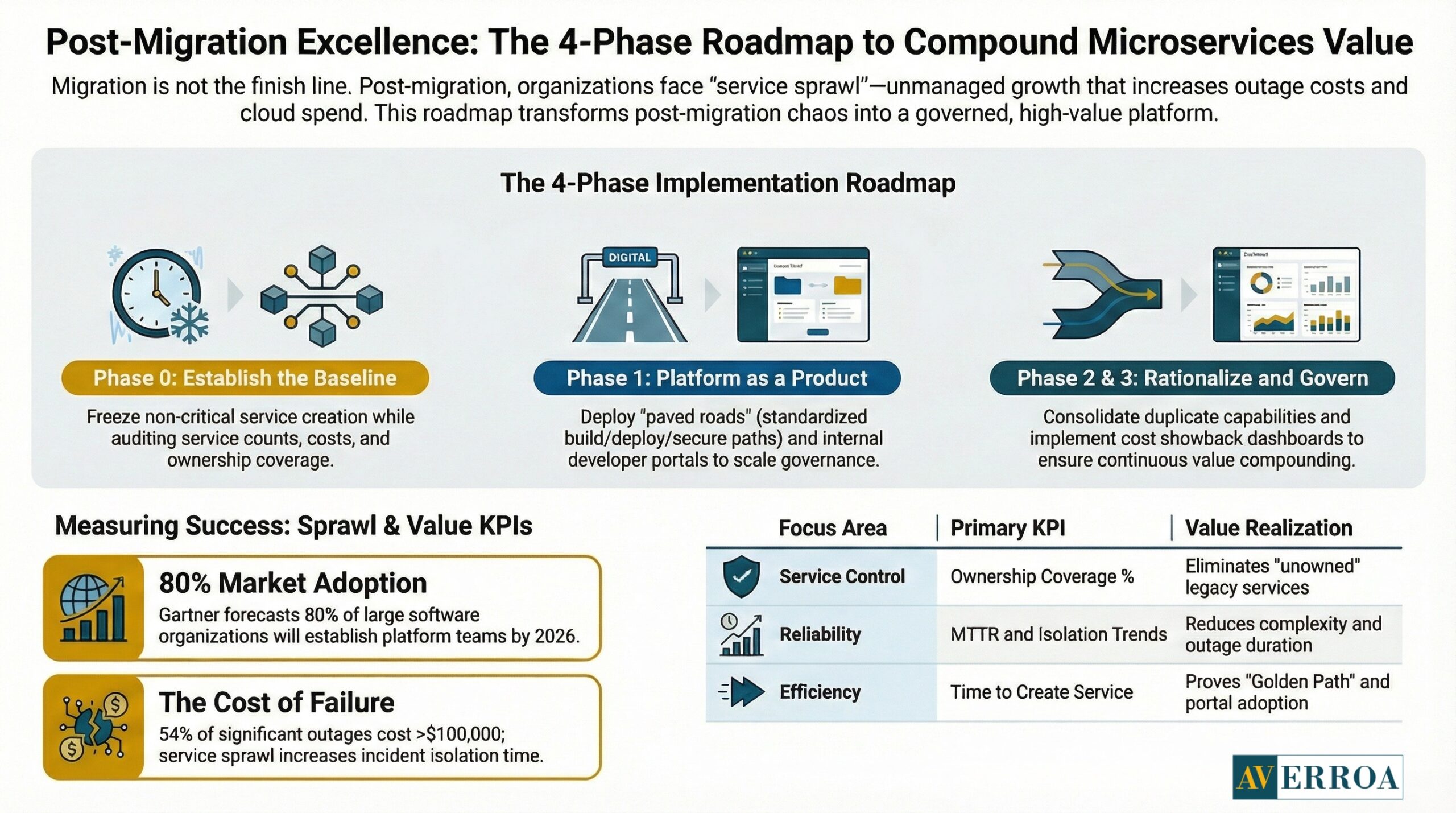
Phase 0: establish the baseline and define “sprawl signals”
Deliverables:
- Service catalogue baseline: count of services, owners, criticality, dependencies
- Operational baseline: incident volume, MTTR, top 10 recurring issues
- Cost baseline: spend by environment, telemetry retention, and idle capacity estimates
- Developer experience baseline: time to create a new service, time to deploy, time to find owners
Guardrails:
- Freeze net new service creation for non-critical work until owners and catalogue coverage exist
- Require ownership and tagging for any service touching production
Typical failure mode: the organisation keeps creating services while trying to implement governance. This doubles the backlog.
Phase 1: Stand up the platform team as a product
Deliverables:
- Golden path templates: build, deploy, observe, secure
- Internal portal or catalogue integration
- Standard runbook format and incident tooling integration
- Policy gates in CI/CD for ownership, telemetry, and security
Pitfall: Platform team treated as central IT, not a product. Adoption stalls, and service sprawl persists.
Phase 2: service lifecycle management and rationalisation
Deliverables:
- Deprecation policy and retirement workflow
- Identified overlaps, duplicate capabilities, and duplicate data pipelines
- Consolidation plan for low-value services
Pitfall: rationalisation becomes political. Prevent this by using evidence: usage, incidents, and cost.
Phase 3: cost and reliability governance loops
Deliverables:
- Showback dashboards by service owner
- SLO and error budget reporting for critical journeys
- Quarterly “sprawl review” that retires services and reduces dependencies
This phase connects directly to cost pressure. Flexera’s figures on cloud spend management challenges make the business case for continuous governance, not annual cost reduction exercises.
KPIs and value realisation
To prove you are winning against service sprawl, track KPIs that reflect control, not just activity.
Service sprawl control:
- Percentage of services with named owners and on-call policy
- Percentage of services with standard telemetry and runbooks
- Number of deprecated services retired per quarter
- Dependency depth for critical journeys, measured as call chain length and number of cross-domain dependencies
Platform and developer experience:
- Time to create a new service using the golden path
- Time to deploy to production safely
- Portal adoption, percentage of teams using the catalogue for ownership and runbooks
Reliability and cost:
- Incident recurrence rate for the top 10 issues
- MTTR trend and time to isolate trend
- Cost per journey or cost per workflow run, owned by product teams
- Telemetry retention cost trend and environment sprawl trend
Anonymised example, EU
An EU enterprise exited migration with 140 services and rising operational costs. They treated service sprawl as a year two programme. A platform team introduced a golden path, enforced ownership tags, and retired low usage services quarterly. Within two quarters, incident recurrence reduced, and onboarding of new services became consistent. The measurable shift was not the service count. It was ownership coverage and standardisation coverage.
Actionable Takeaways
- Treat service sprawl as a predictable year two risk, and fund it like a programme, not an afterthought.
- Create a service catalogue and make ownership mandatory. Services without owners become legacy immediately.
- Establish a platform team with product posture and adoption KPIs, because the market is converging on platform engineering as the scaling model.
- Use internal developer experience as a control mechanism, paved roads reduce inconsistency and reduce sprawl.
- Manage plurality deliberately. Many organisations run multiple platforms; the key is consistent standards and governance.
- Put explicit service lifecycle states in place and retire services continuously.
- Tie cost ownership to services and journeys, because cloud spend pressure is already the executive constraint.
- Make reliability and observability non-negotiable, since outage costs routinely exceed $100,000 and sometimes exceed $1 million.
- If service sprawl signals worsen, pause net new services and fix governance coverage first.
If you want to modernise and then keep the estate governable, start with Enterprise custom development services to build the operating model, platform guardrails, and lifecycle governance that prevents service sprawl.
References
- Gartner platform engineering forecast: https://www.gartner.com/en/infrastructure-and-it-operations-leaders/topics/platform-engineering
- DORA platform engineering capability: https://dora.dev/capabilities/platform-engineering/
- State of Platform Engineering Vol 4: https://platformengineering.org/blog/announcing-the-state-of-platform-engineering-vol-4
- Port IDP report: https://www.port.io/blog/the-2024-state-of-internal-developer-portal-report
- CNCF Backstage adoption blog: https://www.cncf.io/blog/2024/11/15/internal-developer-platforms-at-scale-with-the-certified-backstage-associate-cba-certification/
- Flexera State of the Cloud 2025 press release: https://www.flexera.com/about-us/press-center/new-flexera-report-finds-84-percent-of-organizations-struggle-to-manage-cloud-spend
- Uptime Institute outage executive summary PDF: https://datacenter.uptimeinstitute.com/rs/711-RIA-145/images/2024.Resiliency.Survey.ExecSum.pdf
- CNCF Annual Cloud Native Survey: https://www.cncf.io/reports/the-cncf-annual-cloud-native-survey/
Life After Migration: How to Avoid Service Sprawl When Microservices Become Legacy
Most organisations worry about the migration itself. The quieter risk arrives 12 to 24 months later: service sprawl. Teams keep shipping services, the catalogue grows, ownership blurs, and the platform becomes harder to change than the monolith it replaced. That is how microservices become the new legacy.
The timing is not theoretical. Platform engineering is accelerating precisely because complexity has outgrown informal practices. Gartner forecasts that by 2026, 80% of large software engineering organisations will establish platform engineering teams, up from 45% in 2022. DORA reports that by 2025, 90% of organisations use an internal developer platform and 76% have dedicated platform teams. This is the market acknowledging that “let every team build their own path” does not scale.
Cost pressure makes the problem sharper. Flexera reports 84% of respondents say managing cloud spend is the top cloud challenge, and cloud spend is expected to rise 28% in the coming year. In other words, you cannot afford uncontrolled growth in services, environments, telemetry, and duplicated data.
This final article is about the long game: how to prevent service sprawl, how platform teams and internal developer experience keep delivery fast, and which KPIs prove that microservices are still earning their keep.
Service sprawl is the new legacy: what it looks like and why it happens
Service sprawl is not “too many services”. It is unmanaged growth in services, dependencies, and operational obligations relative to the organisation’s ability to govern them.
In practice, service sprawl shows up as five symptoms that leaders can recognise without reading code.
- Ownership dilution
A service exists, but no one feels accountable for its reliability, its cost, or its roadmap. On call rotates without context. Incidents become escalations. - Dependency fog
No one can answer “what breaks if we change this” without tribal knowledge. Tracing exists, but dependency mapping is incomplete. - Inconsistent ways of working
Different teams use different build systems, deployment patterns, secrets handling, and logging formats. Standardisation happens in meetings, not in paved roads. - Portfolio drift
Services overlap. Business rules are duplicated. Data is copied into multiple stores. Reconciliation becomes operational debt. - Cost surfaces multiply
Environments remain alive “just in case”. Observability retention grows by default. Data pipelines and caches duplicate.
The result is predictable: microservices become a legacy estate, just distributed.
Business impact and risk
Service sprawl increases outage probability and recovery time because there are more moving parts and weaker ownership. Outage economics are not forgiving. Uptime Institute’s Annual Outage Analysis 2024 executive summary reports that 54% of respondents said their most recent significant outage cost more than $100,000, and 16% said it cost more than $1 million. Service sprawl does not create every outage, but it reliably increases incident complexity and the time required to isolate root causes.
Cost is the second pressure point. Flexera reports 84% of respondents see cloud spend management as the top cloud challenge, with expected cloud spend growth of 28% in the coming year. When service sprawl increases telemetry, data duplication, and parallel environments, it pushes directly into that cost challenge.
What changes in operating model and governance
In a monolith, architecture governance can be centralised. In microservices, central governance becomes a bottleneck unless it is converted into automation and clear guardrails.
Service sprawl is often the outcome of an “independent teams at all costs” interpretation. Independence needs constraints. That is a traditional enterprise lesson that still applies: freedom without standards becomes chaos. Modern practice simply moves standards into platforms, templates, and policy controls.
Architecture and integration implications
Service sprawl grows when interfaces are treated as an afterthought. Every service creates more contracts and versioning pressure. The cure is not heavier review boards. The cure is explicit lifecycle management: service catalogues, contract policies, and deprecation paths that are visible and enforced.
Anonymised example, EU
A regulated enterprise migrated core case management into services and hit service sprawl by year two. The service count grew, but no consistent ownership model existed for shared libraries, queues, and integration adapters. The organisation stabilised by creating a service catalogue with owners, defining “critical journey” owners across services, and enforcing standard observability and security templates. The key shift was governance. It became executable, not advisory.
Platform teams are the control plane for service sprawl
Platform engineering exists because service sprawl is a scaling limit. The evidence is increasingly explicit.
Gartner forecasts that by 2026, 80% of large software engineering organisations will establish platform engineering teams, up from 45% in 2022. DORA goes further, reporting that by 2025 adoption of internal developer platforms is 90%, with 76% establishing dedicated platform teams. The implication is direct: enterprises are normalising the idea that developer enablement is a product, and that product must be owned.
Platform teams prevent service sprawl by doing three things:
1) Providing paved roads
A paved road is a standard way to build, deploy, secure, and observe services. It makes the right thing easy, and the risky thing harder. This is how you scale governance without scaling bureaucracy.
2) Making ownership visible
A platform can enforce ownership metadata. Services without an owner cannot pass certain gates. That is a simple rule that reduces service sprawl quickly.
3) Reducing cognitive load with internal developer experience
Service sprawl is often a cognitive load problem. Developers spend time navigating tooling and policy rather than shipping value.
Internal developer portals and catalogues address this. One market signal is the 2024 internal developer portal report by Port, which states that almost 85% of surveyed companies have either started implementing a portal (50%) or plan to do so in the next year (35%). The implication is not that portals are mandatory. The implication is that discoverability and standards are becoming essential as estates grow.
Backstage is a concrete ecosystem reference point. CNCF’s own blog notes Backstage has more than 3,000 adopters and 2,000 contributors worldwide, and as of October 2024 has over 270 public adopters. This matters because it signals that service catalogues and portals are no longer niche. They are becoming standard tooling in the fight against service sprawl.
Operating model and governance changes
Platform teams need a product posture. They require a roadmap, SLAs, adoption metrics, and explicit decision rights. Otherwise they become a ticket queue, and service sprawl continues.
A useful reality check comes from the State of Platform Engineering Vol 4 report, which found 55.9% of companies operate more than one platform. The implication is that “one platform to rule them all” is not the goal. The goal is controlled plurality with consistent standards. Multiple platforms can be rational if they are intentionally designed and governed.
Anonymised example, MENA
A fast-growing enterprise built multiple microservice teams with high autonomy. Service sprawl followed: inconsistent pipelines, duplicated authentication adapters, and uneven logging. A platform team introduced golden path templates and an internal portal that made service ownership and runbooks discoverable. Service sprawl did not disappear, but it stopped accelerating because teams defaulted to standard patterns.
Architecture hygiene that prevents service sprawl: lifecycle, standards, and limits
Service sprawl is ultimately a lifecycle management problem. The architecture needs constraints that make growth sustainable.
Set explicit service lifecycle states
Treat services like products. Define states such as: proposed, active, deprecated, retired. Enforce these in the catalogue and CI policies.
Standardise what must be consistent
Standards that matter for service sprawl control:
- Identity patterns for service-to-service access
- Logging, metrics, and tracing conventions
- API versioning and deprecation policy
- Data ownership rules and replication constraints
- Incident runbooks and escalation paths
These standards should be delivered as templates and checks. Meeting-based governance does not scale.
Put limits where it hurts, not where it is comfortable
A practical anti-sprawl rule set:
- No production service without an owner, on-call policy, and runbook.
- No new service without a cost attribution tag and a unit cost hypothesis.
- No public API without versioning and deprecation dates.
- No shared database writes across services.
- No long-lived environments without an expiry policy.
Architecture and integration implications
Service sprawl tends to increase coupling through accidental dependency chains. A catalogue helps map dependencies, but you also need integration discipline. Events and APIs should reduce coupling, not multiply it. This is where consistent schema governance and contract testing pay back.
A market-level context for why discipline matters: CNCF’s Annual Cloud Native Survey (Jan 20, 2026) reports that 82% of container users are running Kubernetes. Kubernetes ubiquity makes it easy to create new deployable units. That is positive. It also makes it easy to create ungoverned sprawl. The differentiator becomes the platform and governance layer above it.
Implementation approach: the post-migration programme that keeps value compounding
Most organisations treat migration as a programme. They should treat post-migration as a programme too. Service sprawl is the reason.
Phase 0: establish the baseline and define “sprawl signals”
Deliverables:
- Service catalogue baseline: count of services, owners, criticality, dependencies
- Operational baseline: incident volume, MTTR, top 10 recurring issues
- Cost baseline: spend by environment, telemetry retention, and idle capacity estimates
- Developer experience baseline: time to create a new service, time to deploy, time to find owners
Guardrails:
- Freeze net new service creation for non-critical work until owners and catalogue coverage exist
- Require ownership and tagging for any service touching production
Typical failure mode: the organisation keeps creating services while trying to implement governance. This doubles the backlog.
Phase 1: Stand up the platform team as a product
Deliverables:
- Golden path templates: build, deploy, observe, secure
- Internal portal or catalogue integration
- Standard runbook format and incident tooling integration
- Policy gates in CI/CD for ownership, telemetry, and security
Pitfall: Platform team treated as central IT, not a product. Adoption stalls, and service sprawl persists.
Phase 2: service lifecycle management and rationalisation
Deliverables:
- Deprecation policy and retirement workflow
- Identified overlaps, duplicate capabilities, and duplicate data pipelines
- Consolidation plan for low-value services
Pitfall: rationalisation becomes political. Prevent this by using evidence: usage, incidents, and cost.
Phase 3: cost and reliability governance loops
Deliverables:
- Showback dashboards by service owner
- SLO and error budget reporting for critical journeys
- Quarterly “sprawl review” that retires services and reduces dependencies
This phase connects directly to cost pressure. Flexera’s figures on cloud spend management challenges make the business case for continuous governance, not annual cost reduction exercises.
KPIs and value realisation
To prove you are winning against service sprawl, track KPIs that reflect control, not just activity.
Service sprawl control:
- Percentage of services with named owners and on-call policy
- Percentage of services with standard telemetry and runbooks
- Number of deprecated services retired per quarter
- Dependency depth for critical journeys, measured as call chain length and number of cross-domain dependencies
Platform and developer experience:
- Time to create a new service using the golden path
- Time to deploy to production safely
- Portal adoption, percentage of teams using the catalogue for ownership and runbooks
Reliability and cost:
- Incident recurrence rate for the top 10 issues
- MTTR trend and time to isolate trend
- Cost per journey or cost per workflow run, owned by product teams
- Telemetry retention cost trend and environment sprawl trend
Anonymised example, EU
An EU enterprise exited migration with 140 services and rising operational costs. They treated service sprawl as a year two programme. A platform team introduced a golden path, enforced ownership tags, and retired low usage services quarterly. Within two quarters, incident recurrence reduced, and onboarding of new services became consistent. The measurable shift was not the service count. It was ownership coverage and standardisation coverage.
Actionable Takeaways
- Treat service sprawl as a predictable year two risk, and fund it like a programme, not an afterthought.
- Create a service catalogue and make ownership mandatory. Services without owners become legacy immediately.
- Establish a platform team with product posture and adoption KPIs, because the market is converging on platform engineering as the scaling model.
- Use internal developer experience as a control mechanism, paved roads reduce inconsistency and reduce sprawl.
- Manage plurality deliberately. Many organisations run multiple platforms; the key is consistent standards and governance.
- Put explicit service lifecycle states in place and retire services continuously.
- Tie cost ownership to services and journeys, because cloud spend pressure is already the executive constraint.
- Make reliability and observability non-negotiable, since outage costs routinely exceed $100,000 and sometimes exceed $1 million.
- If service sprawl signals worsen, pause net new services and fix governance coverage first.
If you want to modernise and then keep the estate governable, start with Enterprise custom development services to build the operating model, platform guardrails, and lifecycle governance that prevents service sprawl.
References
- Gartner platform engineering forecast: https://www.gartner.com/en/infrastructure-and-it-operations-leaders/topics/platform-engineering
- DORA platform engineering capability: https://dora.dev/capabilities/platform-engineering/
- State of Platform Engineering Vol 4: https://platformengineering.org/blog/announcing-the-state-of-platform-engineering-vol-4
- Port IDP report: https://www.port.io/blog/the-2024-state-of-internal-developer-portal-report
- CNCF Backstage adoption blog: https://www.cncf.io/blog/2024/11/15/internal-developer-platforms-at-scale-with-the-certified-backstage-associate-cba-certification/
- Flexera State of the Cloud 2025 press release: https://www.flexera.com/about-us/press-center/new-flexera-report-finds-84-percent-of-organizations-struggle-to-manage-cloud-spend
- Uptime Institute outage executive summary PDF: https://datacenter.uptimeinstitute.com/rs/711-RIA-145/images/2024.Resiliency.Survey.ExecSum.pdf
- CNCF Annual Cloud Native Survey: https://www.cncf.io/reports/the-cncf-annual-cloud-native-survey/
Meet The Author
Meet The Author

Senior software engineer focused on backend systems and Android apps, delivering scalable web/mobile/cloud solutions. Leads technical direction, mentors teams, and ships high-performance services using ASP.NET Core/C#, microservices, and cloud-native infrastructure.
Senior software engineer focused on backend systems and Android apps, delivering scalable web/mobile/cloud solutions. Leads technical direction, mentors teams, and ships high-performance services using ASP.NET Core/C#, microservices, and cloud-native infrastructure.
Averroa Principal