The Strangler Fig Pattern: Safely Decomposing a Monolith Over Time
The strangler fig pattern has become the default migration play for a reason. It lets enterprises modernise without betting the business on a big bang cutover. That matters now because most organisations are under pressure to deliver faster while costs and risk are moving in the opposite direction. Gartner predicts 25% of organisations will experience significant dissatisfaction with cloud adoption by 2028, driven by unrealistic expectations, suboptimal implementation, and uncontrolled costs. Flexera reports that 84% of organisations struggle to manage cloud spend, and cloud spend is expected to rise 28% in the coming year. Those pressures make “rewrite it all” a governance problem, not just a technical one.
The strangler fig pattern reduces exposure by shifting modernisation into an incremental operating rhythm: route a slice of traffic to new capability, prove stability, then expand. Martin Fowler’s original argument was blunt: strangler approaches reduce risk and allow steady value delivery, with frequent releases that make progress visible.
For EU and MENA leaders, the strategic question is not whether microservices are fashionable. The question is whether your organisation can modernise while staying audit ready, resilient, and in control of customer experience. The strangler approach is how you do that without theatre.
Why the strangler fig pattern beats the rewrite gamble
Enterprise leaders do not fear modern architecture. They fear losing control: outages, audit findings, cost overruns, and stakeholder fatigue. The strangler fig pattern is a risk management response to those realities.
Martin Fowler coined the metaphor in 2004 and made the core business case explicit: a strangler approach reduces risk versus a cutover rewrite, delivers value steadily, and benefits from short release cycles that make progress easier to monitor. In 2024, Fowler revisited the concept and noted that traffic to the original page had grown to about 5,000 views per month, which is a useful signal of how common this modernisation need has become.
From an executive lens, the strangler approach changes the risk profile in three concrete ways.
First, it reduces the size of any single decision. Instead of approving a multi year rewrite with a single delivery date, you approve a sequence of bounded migrations with measurable checkpoints.
Second, it creates options. You can pause, pivot, or stop after a slice has been migrated if the value case does not hold.
Third, it forces operational truth early. You learn how the new stack behaves under real traffic and real data volumes, not staged assumptions.
This is not purely technical hygiene. Security and resilience economics are brutal. IBM’s Cost of a Data Breach Report 2024 puts the average cost of a breach at USD 4.88 million, up from USD 4.45 million in 2023, a 10% jump. Modernisation that increases attack surface without compensating controls is value destructive.
Anonymised example: a regulated EU financial services firm planned a full core workflow rewrite. The programme slipped 9 months, then scope expanded, then performance defects appeared late. They pivoted to the strangler fig pattern by fronting the monolith with a routing layer and carving out onboarding and document processing first. That reduced release friction and created an incremental audit trail of controls.
How the strangler fig pattern works in modern enterprises
At its simplest, the strangler fig pattern introduces an intermediary between users and the legacy system, then gradually routes more requests to new services until the legacy components can be retired.
Microsoft’s cloud architecture guidance summarises the pattern clearly: start by introducing a facade or proxy between clients, the legacy system, and the new system, then route most requests to the legacy system at first and migrate incrementally.
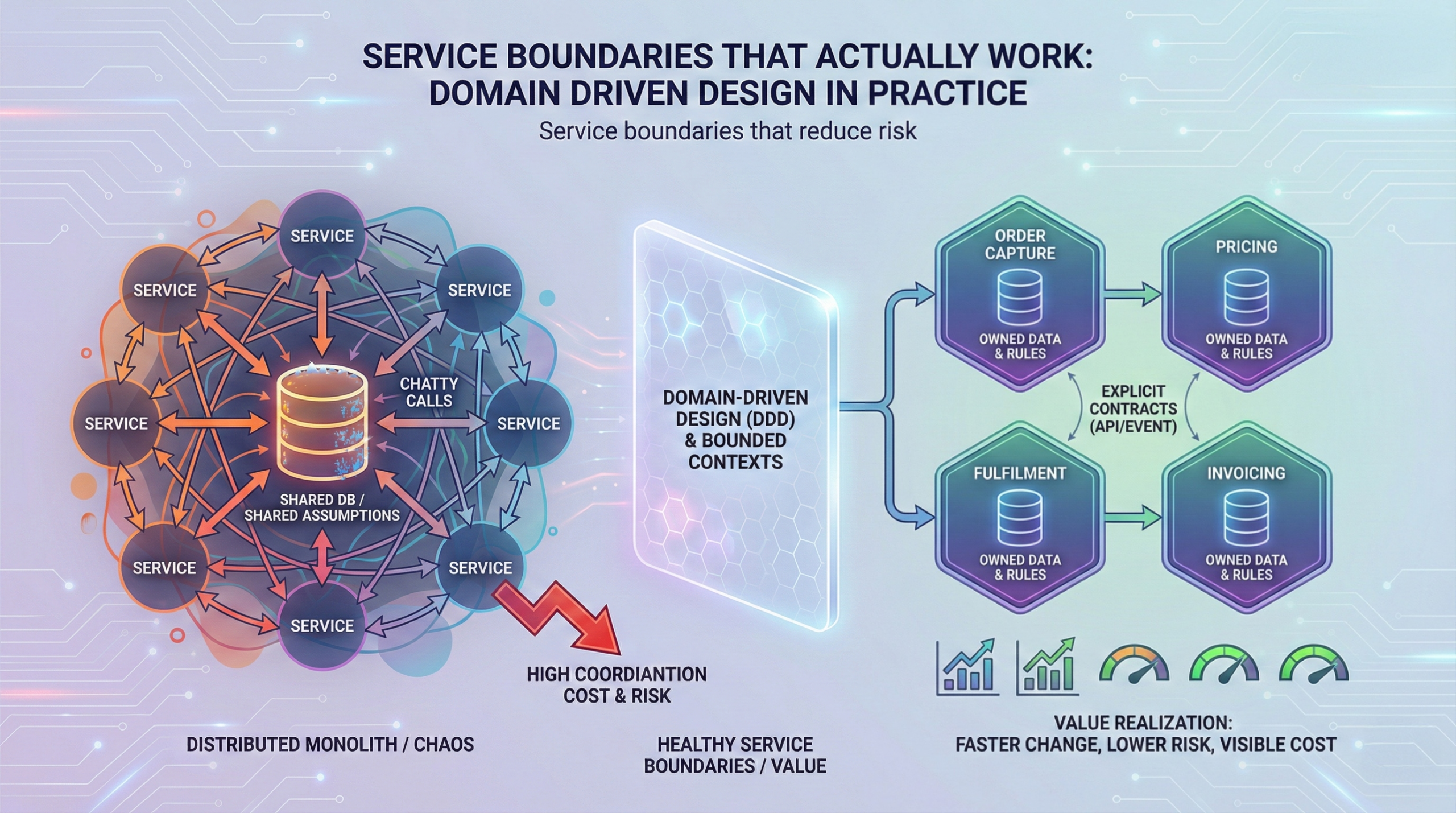
In practice, there are four common variants, and choosing the wrong one is where many programmes create a “distributed monolith”.
- Edge strangling via routing
You put a gateway, reverse proxy, or BFF layer in front, then route by URL, tenant, feature, or user segment. This is usually the fastest start, and it is often the least invasive. - Branch by abstraction inside the monolith
You build an abstraction layer, then switch implementations behind it. This is slower to start, but it reduces cross system integration complexity later. - Data first strangling
You establish new data ownership boundaries and pipelines, then migrate reads and writes. This is essential when shared database coupling is the real constraint. - Workflow first strangling
For enterprises with heavy approvals, SLAs, and audit requirements, you strangle by business process. You move workflow steps to a new orchestration layer while keeping legacy record systems stable.
Leaders should expect the pattern to be anchored in delivery capability, not diagrams. CircleCI’s 2024 report is a good benchmark signal: they analysed nearly 15 million data points and found throughput up 11% across all branches and 68% on production branches, and median recovery from errors under 60 minutes for the first time. The message is not “copy these numbers”. The message is that modern delivery expectations are rising, and strangler programmes must build delivery muscle as they migrate.
Anonymised example: a MENA logistics enterprise used edge routing to move pricing and quoting to a new service. They deliberately did not touch core shipment execution first. They measured business value through quote cycle time and conversion, and measured platform health through error rates, latency, and rollback frequency. Only when those KPIs stabilised did they expand the routing footprint.
Operating model and governance changes that make it safe
The strangler fig pattern is not just an engineering technique. It is an operating model change, because it creates two truths in production at the same time: legacy and new.
Decision makers should make three governance changes explicit.
1) From project milestones to migration tranches
Replace “go live” milestones with tranche gates such as:
- tranche scope, what is being routed and why
- acceptance criteria, including SLOs and security controls
- rollback design, how to retreat safely
- audit evidence, what artefacts prove controls and approvals
This is a traditional governance move, but applied to modern delivery. It respects how enterprises manage risk, while still enabling speed.
2) From central approval to guardrails
Central architecture boards that approve every interface change do not scale under strangler delivery. Governance must shift into reusable standards and automated checks.
CNCF’s Annual Survey 2024 found that 38% of respondents reported 80% to 100% of releases are automated, and average automated releases increased from 56.5% in 2023 to 59.2% in 2024. That is a useful indicator: many organisations are still mid journey, so governance must meet them where they are. Strangling without high automation creates too much manual effort.
A practical guardrail set for strangler programmes:
- API versioning rules and deprecation policy
- automated security scanning and secrets controls in CI/CD
- mandatory telemetry standards per route migrated
- change management rules for high risk workflows
- cost tagging and chargeback expectations per service
3) Clear ownership for what is routed
Routing slices require ownership clarity. Who owns the customer experience for a transaction that crosses old and new? Without explicit ownership, incidents become blame loops.
Anonymised example: an EU manufacturer built a new order status experience, but the status came from the monolith. When an integration issue surfaced, three teams claimed partial ownership and no one owned incident resolution. The fix was governance, not code: a single accountable product owner for the end to end journey, plus a joint on call rota until the legacy dependency was removed.
Architecture, data, and security implications you cannot ignore
This is where executives should demand specificity. The strangler fig pattern works when integration and data ownership are engineered deliberately.
Integration surface: minimise synchronous coupling
A common failure mode is building new services that still depend on synchronous calls into the monolith for every transaction. That creates a bottleneck and increases outage blast radius.
Use integration tactics that reduce coupling:
- asynchronous events for state changes where possible
- caching and read models for high volume queries
- anti corruption layers to isolate legacy domain models
- contract testing to stabilise interfaces across teams
Data migration: decide what “system of record” means per domain
Strangling often starts at the edge, but it cannot finish until data ownership changes. The decision you must make, early, is whether new capability owns its data or reads legacy indefinitely.
A staged approach that works in practice:
- Phase A: new service reads legacy data via stable interfaces
- Phase B: dual writes with reconciliation for a bounded period
- Phase C: new service becomes system of record, legacy becomes consumer
- Phase D: legacy tables and jobs are retired with explicit evidence
Security and identity: one control plane, two runtimes
Two production truths create identity drift risk. You need consistent authentication, authorisation, and audit logging across both sides.
This risk is not theoretical. IBM’s 2024 breach cost increase highlights how expensive post breach responses and lost business can be. Strangler programmes should treat “security parity” as a gate: every routed capability must meet or exceed legacy controls.
Observability and resilience: avoid blind spots as routing expands
Routing introduces new failure modes: misroutes, partial rollouts, and latency inflation from added hops.
Grafana’s 2025 observability survey reports 67% use Prometheus in production in some capacity, while OpenTelemetry production usage is 41% with 38% investigating or running POCs. The implication is practical: standardised telemetry is becoming normal, but coverage is still uneven. Strangler programmes must invest in tracing and correlation IDs early, otherwise incident diagnosis degrades as the system becomes more distributed.
Implementation approach: a phased strangler fig pattern playbook
This is the execution plan leaders can govern. It treats the strangler fig pattern as a portfolio of small wins with explicit guardrails.
Phase 0: Baseline and target selection
Deliverables:
- route map of top user journeys, endpoints, and batch jobs
- dependency map, especially shared database and shared libraries
- baseline KPIs, including deployment frequency, change failure rate, MTTR, and customer journey SLAs
- security baseline, including IAM, secrets handling, and audit logging
Guardrails:
- no routing without end to end monitoring
- no migration tranche without a rollback path
Typical failure mode: teams pick a “hard but important” domain first and stall.
Phase 1: Build the facade and routing strategy
Deliverables:
- gateway or proxy configuration with routing rules
- traffic segmentation strategy, for example tenant based, user cohort, feature flag
- canonical API contract and versioning policy
- telemetry standards for every routed call
Use Microsoft’s facade guidance as the conceptual baseline, then adapt to your enterprise constraints.
Typical failure mode: routing exists, but policies are manual and inconsistently applied.
Phase 2: Extract the first slice that pays for itself
Choose a slice with clear value, limited coupling, and measurable outcomes. In workflow heavy enterprises, good first slices include notifications, document generation, approvals orchestration, or search.
KPIs:
- percent of traffic routed to new capability
- error rate and latency deltas for routed routes
- release frequency for the new component versus legacy
- business KPI relevant to the slice, for example cycle time reduction
CNCF data points help calibrate automation expectations: only 38% report 80% to 100% automated releases, and average automation is 59.2%. If you are below that, make automation a first class workstream.
Phase 3: Expand, then remove legacy dependencies
This phase is where many programmes plateau. Expansion is easy. Removing legacy dependencies is hard.
Tactics:
- replace synchronous legacy reads with cached read models
- introduce events for key state changes
- migrate ownership of data domain by domain
- retire legacy jobs and tables with operational evidence
Typical failure mode: new services still depend on legacy for core data, creating a permanent integration tax.
Phase 4: Retire legacy components and simplify
Deliverables:
- explicit decommission plan and approvals
- runbooks and incident playbooks updated to new topology
- cost and licence reduction evidence
- final audit artefacts showing control continuity
Executive KPI focus should include cost control. Gartner’s prediction about cloud dissatisfaction due to uncontrolled costs should be treated as a governance warning, not an analyst soundbite. Flexera’s cloud spend pressure data reinforces the point.
Actionable Takeaways
- Use the strangler fig pattern to reduce programme risk by migrating in governed tranches, not a single cutover.
- Front the monolith with a facade or proxy, then route incrementally by cohort, feature, or journey.
- Fund automation and guardrails early, because manual governance does not scale as routing expands.
- Put a single accountable owner over each end to end routed journey, especially when incidents cross old and new.
- Treat data ownership as a staged decision, not a late technical task. Plan for dual writes and reconciliation where needed.
- Make security parity a migration gate, since distributed estates increase control drift risk and breach costs are rising.
- Standardise observability before complexity rises, or MTTR will worsen as the system becomes more distributed.
- Measure progress with traffic migrated, error budgets, and business outcomes, not number of services.
If you are modernising workflow heavy enterprise systems and want an execution plan for incremental decomposition, start with Enterprise Software and Workflow Automation and align your routing strategy, governance guardrails, and value realisation metrics from day one.
References
- Martin Fowler, Original Strangler Fig Application (Jun 29, 2004) → https://martinfowler.com/bliki/OriginalStranglerFigApplication.html
- Microsoft Azure Architecture Center, Strangler Fig pattern (Feb 19, 2025) → https://learn.microsoft.com/en-us/azure/architecture/patterns/strangler-fig
- CNCF Annual Survey 2024 report PDF (published 2025) → https://www.cncf.io/wp-content/uploads/2025/04/cncf_annual_survey24_031225a.pdf
- CircleCI The 2024 State of Software Delivery PDF (2024) → https://circleci.com/landing-pages/assets/CircleCI-The-2024-State-of-Software-Delivery.pdf
- Flexera press release on cloud spend challenges (Mar 19, 2025) → https://www.flexera.com/about-us/press-center/new-flexera-report-finds-84-percent-of-organizations-struggle-to-manage-cloud-spend
- Gartner press release on cloud dissatisfaction prediction (May 13, 2025) → https://www.gartner.com/en/newsroom/press-releases/2025-05-13-gartner-identifies-top-trends-shaping-the-future-of-cloud
- Grafana Observability Survey Report 2025 (2025) → https://grafana.com/observability-survey/2025/
- IBM Cost of a Data Breach Report 2024 PDF (Jul 2024) → https://wp.table.media/wp-content/uploads/2024/07/30132828/Cost-of-a-Data-Breach-Report-2024.pdf
The Strangler Fig Pattern: Safely Decomposing a Monolith Over Time
The strangler fig pattern has become the default migration play for a reason. It lets enterprises modernise without betting the business on a big bang cutover. That matters now because most organisations are under pressure to deliver faster while costs and risk are moving in the opposite direction. Gartner predicts 25% of organisations will experience significant dissatisfaction with cloud adoption by 2028, driven by unrealistic expectations, suboptimal implementation, and uncontrolled costs. Flexera reports that 84% of organisations struggle to manage cloud spend, and cloud spend is expected to rise 28% in the coming year. Those pressures make “rewrite it all” a governance problem, not just a technical one.
The strangler fig pattern reduces exposure by shifting modernisation into an incremental operating rhythm: route a slice of traffic to new capability, prove stability, then expand. Martin Fowler’s original argument was blunt: strangler approaches reduce risk and allow steady value delivery, with frequent releases that make progress visible.
For EU and MENA leaders, the strategic question is not whether microservices are fashionable. The question is whether your organisation can modernise while staying audit ready, resilient, and in control of customer experience. The strangler approach is how you do that without theatre.
Why the strangler fig pattern beats the rewrite gamble
Enterprise leaders do not fear modern architecture. They fear losing control: outages, audit findings, cost overruns, and stakeholder fatigue. The strangler fig pattern is a risk management response to those realities.
Martin Fowler coined the metaphor in 2004 and made the core business case explicit: a strangler approach reduces risk versus a cutover rewrite, delivers value steadily, and benefits from short release cycles that make progress easier to monitor. In 2024, Fowler revisited the concept and noted that traffic to the original page had grown to about 5,000 views per month, which is a useful signal of how common this modernisation need has become.
From an executive lens, the strangler approach changes the risk profile in three concrete ways.
First, it reduces the size of any single decision. Instead of approving a multi year rewrite with a single delivery date, you approve a sequence of bounded migrations with measurable checkpoints.
Second, it creates options. You can pause, pivot, or stop after a slice has been migrated if the value case does not hold.
Third, it forces operational truth early. You learn how the new stack behaves under real traffic and real data volumes, not staged assumptions.
This is not purely technical hygiene. Security and resilience economics are brutal. IBM’s Cost of a Data Breach Report 2024 puts the average cost of a breach at USD 4.88 million, up from USD 4.45 million in 2023, a 10% jump. Modernisation that increases attack surface without compensating controls is value destructive.
Anonymised example: a regulated EU financial services firm planned a full core workflow rewrite. The programme slipped 9 months, then scope expanded, then performance defects appeared late. They pivoted to the strangler fig pattern by fronting the monolith with a routing layer and carving out onboarding and document processing first. That reduced release friction and created an incremental audit trail of controls.
How the strangler fig pattern works in modern enterprises
At its simplest, the strangler fig pattern introduces an intermediary between users and the legacy system, then gradually routes more requests to new services until the legacy components can be retired.
Microsoft’s cloud architecture guidance summarises the pattern clearly: start by introducing a facade or proxy between clients, the legacy system, and the new system, then route most requests to the legacy system at first and migrate incrementally.
In practice, there are four common variants, and choosing the wrong one is where many programmes create a “distributed monolith”.
- Edge strangling via routing
You put a gateway, reverse proxy, or BFF layer in front, then route by URL, tenant, feature, or user segment. This is usually the fastest start, and it is often the least invasive. - Branch by abstraction inside the monolith
You build an abstraction layer, then switch implementations behind it. This is slower to start, but it reduces cross system integration complexity later. - Data first strangling
You establish new data ownership boundaries and pipelines, then migrate reads and writes. This is essential when shared database coupling is the real constraint. - Workflow first strangling
For enterprises with heavy approvals, SLAs, and audit requirements, you strangle by business process. You move workflow steps to a new orchestration layer while keeping legacy record systems stable.
Leaders should expect the pattern to be anchored in delivery capability, not diagrams. CircleCI’s 2024 report is a good benchmark signal: they analysed nearly 15 million data points and found throughput up 11% across all branches and 68% on production branches, and median recovery from errors under 60 minutes for the first time. The message is not “copy these numbers”. The message is that modern delivery expectations are rising, and strangler programmes must build delivery muscle as they migrate.
Anonymised example: a MENA logistics enterprise used edge routing to move pricing and quoting to a new service. They deliberately did not touch core shipment execution first. They measured business value through quote cycle time and conversion, and measured platform health through error rates, latency, and rollback frequency. Only when those KPIs stabilised did they expand the routing footprint.
Operating model and governance changes that make it safe
The strangler fig pattern is not just an engineering technique. It is an operating model change, because it creates two truths in production at the same time: legacy and new.
Decision makers should make three governance changes explicit.
1) From project milestones to migration tranches
Replace “go live” milestones with tranche gates such as:
- tranche scope, what is being routed and why
- acceptance criteria, including SLOs and security controls
- rollback design, how to retreat safely
- audit evidence, what artefacts prove controls and approvals
This is a traditional governance move, but applied to modern delivery. It respects how enterprises manage risk, while still enabling speed.
2) From central approval to guardrails
Central architecture boards that approve every interface change do not scale under strangler delivery. Governance must shift into reusable standards and automated checks.
CNCF’s Annual Survey 2024 found that 38% of respondents reported 80% to 100% of releases are automated, and average automated releases increased from 56.5% in 2023 to 59.2% in 2024. That is a useful indicator: many organisations are still mid journey, so governance must meet them where they are. Strangling without high automation creates too much manual effort.
A practical guardrail set for strangler programmes:
- API versioning rules and deprecation policy
- automated security scanning and secrets controls in CI/CD
- mandatory telemetry standards per route migrated
- change management rules for high risk workflows
- cost tagging and chargeback expectations per service
3) Clear ownership for what is routed
Routing slices require ownership clarity. Who owns the customer experience for a transaction that crosses old and new? Without explicit ownership, incidents become blame loops.
Anonymised example: an EU manufacturer built a new order status experience, but the status came from the monolith. When an integration issue surfaced, three teams claimed partial ownership and no one owned incident resolution. The fix was governance, not code: a single accountable product owner for the end to end journey, plus a joint on call rota until the legacy dependency was removed.
Architecture, data, and security implications you cannot ignore
This is where executives should demand specificity. The strangler fig pattern works when integration and data ownership are engineered deliberately.
Integration surface: minimise synchronous coupling
A common failure mode is building new services that still depend on synchronous calls into the monolith for every transaction. That creates a bottleneck and increases outage blast radius.
Use integration tactics that reduce coupling:
- asynchronous events for state changes where possible
- caching and read models for high volume queries
- anti corruption layers to isolate legacy domain models
- contract testing to stabilise interfaces across teams
Data migration: decide what “system of record” means per domain
Strangling often starts at the edge, but it cannot finish until data ownership changes. The decision you must make, early, is whether new capability owns its data or reads legacy indefinitely.
A staged approach that works in practice:
- Phase A: new service reads legacy data via stable interfaces
- Phase B: dual writes with reconciliation for a bounded period
- Phase C: new service becomes system of record, legacy becomes consumer
- Phase D: legacy tables and jobs are retired with explicit evidence
Security and identity: one control plane, two runtimes
Two production truths create identity drift risk. You need consistent authentication, authorisation, and audit logging across both sides.
This risk is not theoretical. IBM’s 2024 breach cost increase highlights how expensive post breach responses and lost business can be. Strangler programmes should treat “security parity” as a gate: every routed capability must meet or exceed legacy controls.
Observability and resilience: avoid blind spots as routing expands
Routing introduces new failure modes: misroutes, partial rollouts, and latency inflation from added hops.
Grafana’s 2025 observability survey reports 67% use Prometheus in production in some capacity, while OpenTelemetry production usage is 41% with 38% investigating or running POCs. The implication is practical: standardised telemetry is becoming normal, but coverage is still uneven. Strangler programmes must invest in tracing and correlation IDs early, otherwise incident diagnosis degrades as the system becomes more distributed.
Implementation approach: a phased strangler fig pattern playbook
This is the execution plan leaders can govern. It treats the strangler fig pattern as a portfolio of small wins with explicit guardrails.
Phase 0: Baseline and target selection
Deliverables:
- route map of top user journeys, endpoints, and batch jobs
- dependency map, especially shared database and shared libraries
- baseline KPIs, including deployment frequency, change failure rate, MTTR, and customer journey SLAs
- security baseline, including IAM, secrets handling, and audit logging
Guardrails:
- no routing without end to end monitoring
- no migration tranche without a rollback path
Typical failure mode: teams pick a “hard but important” domain first and stall.
Phase 1: Build the facade and routing strategy
Deliverables:
- gateway or proxy configuration with routing rules
- traffic segmentation strategy, for example tenant based, user cohort, feature flag
- canonical API contract and versioning policy
- telemetry standards for every routed call
Use Microsoft’s facade guidance as the conceptual baseline, then adapt to your enterprise constraints.
Typical failure mode: routing exists, but policies are manual and inconsistently applied.
Phase 2: Extract the first slice that pays for itself
Choose a slice with clear value, limited coupling, and measurable outcomes. In workflow heavy enterprises, good first slices include notifications, document generation, approvals orchestration, or search.
KPIs:
- percent of traffic routed to new capability
- error rate and latency deltas for routed routes
- release frequency for the new component versus legacy
- business KPI relevant to the slice, for example cycle time reduction
CNCF data points help calibrate automation expectations: only 38% report 80% to 100% automated releases, and average automation is 59.2%. If you are below that, make automation a first class workstream.
Phase 3: Expand, then remove legacy dependencies
This phase is where many programmes plateau. Expansion is easy. Removing legacy dependencies is hard.
Tactics:
- replace synchronous legacy reads with cached read models
- introduce events for key state changes
- migrate ownership of data domain by domain
- retire legacy jobs and tables with operational evidence
Typical failure mode: new services still depend on legacy for core data, creating a permanent integration tax.
Phase 4: Retire legacy components and simplify
Deliverables:
- explicit decommission plan and approvals
- runbooks and incident playbooks updated to new topology
- cost and licence reduction evidence
- final audit artefacts showing control continuity
Executive KPI focus should include cost control. Gartner’s prediction about cloud dissatisfaction due to uncontrolled costs should be treated as a governance warning, not an analyst soundbite. Flexera’s cloud spend pressure data reinforces the point.
Actionable Takeaways
- Use the strangler fig pattern to reduce programme risk by migrating in governed tranches, not a single cutover.
- Front the monolith with a facade or proxy, then route incrementally by cohort, feature, or journey.
- Fund automation and guardrails early, because manual governance does not scale as routing expands.
- Put a single accountable owner over each end to end routed journey, especially when incidents cross old and new.
- Treat data ownership as a staged decision, not a late technical task. Plan for dual writes and reconciliation where needed.
- Make security parity a migration gate, since distributed estates increase control drift risk and breach costs are rising.
- Standardise observability before complexity rises, or MTTR will worsen as the system becomes more distributed.
- Measure progress with traffic migrated, error budgets, and business outcomes, not number of services.
If you are modernising workflow heavy enterprise systems and want an execution plan for incremental decomposition, start with Enterprise Software and Workflow Automation and align your routing strategy, governance guardrails, and value realisation metrics from day one.
References
- Martin Fowler, Original Strangler Fig Application (Jun 29, 2004) → https://martinfowler.com/bliki/OriginalStranglerFigApplication.html
- Microsoft Azure Architecture Center, Strangler Fig pattern (Feb 19, 2025) → https://learn.microsoft.com/en-us/azure/architecture/patterns/strangler-fig
- CNCF Annual Survey 2024 report PDF (published 2025) → https://www.cncf.io/wp-content/uploads/2025/04/cncf_annual_survey24_031225a.pdf
- CircleCI The 2024 State of Software Delivery PDF (2024) → https://circleci.com/landing-pages/assets/CircleCI-The-2024-State-of-Software-Delivery.pdf
- Flexera press release on cloud spend challenges (Mar 19, 2025) → https://www.flexera.com/about-us/press-center/new-flexera-report-finds-84-percent-of-organizations-struggle-to-manage-cloud-spend
- Gartner press release on cloud dissatisfaction prediction (May 13, 2025) → https://www.gartner.com/en/newsroom/press-releases/2025-05-13-gartner-identifies-top-trends-shaping-the-future-of-cloud
- Grafana Observability Survey Report 2025 (2025) → https://grafana.com/observability-survey/2025/
- IBM Cost of a Data Breach Report 2024 PDF (Jul 2024) → https://wp.table.media/wp-content/uploads/2024/07/30132828/Cost-of-a-Data-Breach-Report-2024.pdf
Meet The Author
Meet The Author

Senior software engineer focused on backend systems and Android apps, delivering scalable web/mobile/cloud solutions. Leads technical direction, mentors teams, and ships high-performance services using ASP.NET Core/C#, microservices, and cloud-native infrastructure.
Senior software engineer focused on backend systems and Android apps, delivering scalable web/mobile/cloud solutions. Leads technical direction, mentors teams, and ships high-performance services using ASP.NET Core/C#, microservices, and cloud-native infrastructure.
Averroa Principal
Table of content
- The Strangler Fig Pattern: Safely Decomposing a Monolith Over Time
- Why the strangler fig pattern beats the rewrite gamble
- How the strangler fig pattern works in modern enterprises
- Operating model and governance changes that make it safe
- Architecture, data, and security implications you cannot ignore
- Implementation approach: a phased strangler fig pattern playbook
- Actionable Takeaways
- References
- Meet The Author