Data Is the Hard Part: Eventual Consistency and Distributed Transactions
If you are migrating from a monolith to microservices, the hard part is not the APIs or the containers. It is the data. Specifically, it is how you maintain trust in your numbers when you no longer have one database, one transaction boundary, and one place to “just fix it”.
This matters now because most enterprises are scaling digital operations under tighter resilience and compliance expectations. In the EU, NIS2 raised the bar on operational risk and incident readiness, with member state transposition due by 17 October 2024. Meanwhile, data volumes and system interdependence keep rising, which increases the blast radius of “small” inconsistencies. IDC forecasts the global datasphere growing to 175 zettabytes by 2025.
Eventual consistency is therefore not a technical footnote. It is a business policy decision about what can be temporarily wrong, for how long, and with what customer and regulatory consequences. If you do not make that decision explicitly, the system will make it for you, usually during an incident.
Why distributed data breaks programmes, not code
Microservices migration programmes rarely fail because a team cannot build services. They fail because the organisation ships an operating model that cannot run distributed data safely.
Start with the board level risk statement. Outages and data incidents are expensive and reputation compounding. In Uptime Institute’s Annual Outage Analysis 2024, 54 percent of respondents said their most recent significant outage cost more than $100,000, and 16 percent said it cost more than $1 million. Even more pointed, four in five respondents said their most recent serious outage could have been prevented with better practices. This is not a tooling problem. It is governance and execution discipline.
Then add breach exposure. IBM’s Cost of a Data Breach findings for 2024 put the average global breach cost at USD 4.88 million. In microservices, data is replicated, cached, streamed, and transformed across boundaries. If you do not control lineage and access consistently, you multiply audit scope and increase the chance that an operational mistake becomes a compliance event.
A practical way to frame this for decision makers is to ask one uncomfortable question: which numbers must never be wrong, even briefly. Payroll, entitlements, payment status, sanctions screening, clinical safety flags, and regulated reporting fields usually sit in this category. If you cannot ring fence those “must be right now” datasets, your migration sequencing is wrong.
Anonymised example: a regional retailer decomposed its monolith into services and kept “inventory” as an event fed projection for speed. That worked until promotions. During peak load, consumers saw items as “in stock” that were already reserved. The technical issue was lag and duplicate event processing. The business issue was that the organisation had never agreed an acceptable oversell rate, nor a customer recovery playbook. They ended up re introducing synchronous checks for specific SKUs and created a nightly reconciliation job with a clear operational owner. The fix was not heroic engineering. It was making data policy explicit.
Eventual consistency without dogma: choose it, do not inherit it
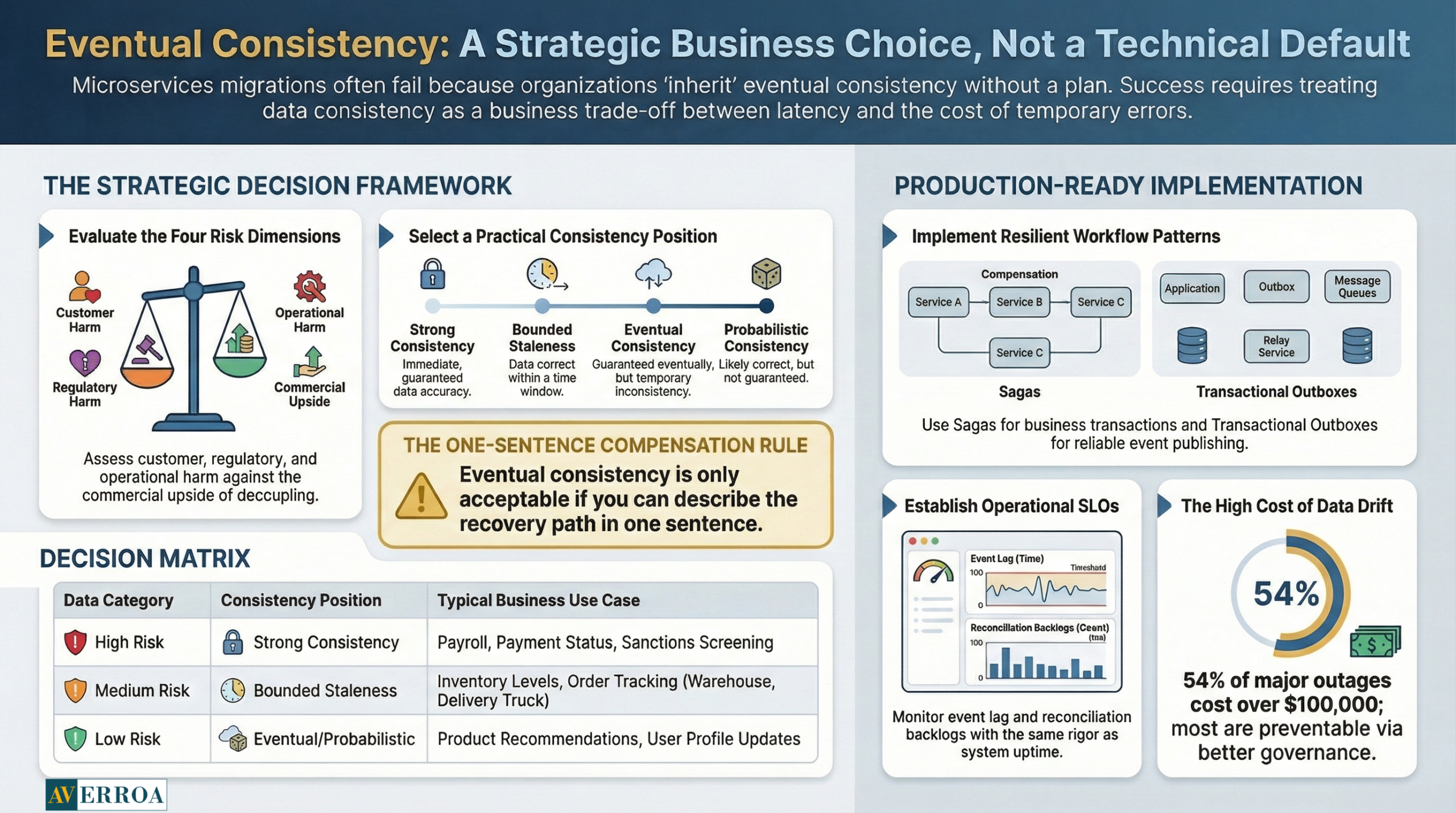
Eventual consistency is often sold as a modern architecture badge. In reality, it is a trade. You are paying with temporary inconsistency to buy availability, latency, autonomy, and deployability.
To keep the discussion grounded, align on three meanings of “consistency” that executives often mix up:
- Transactional consistency inside one database, usually ACID.
- Distributed systems consistency trade offs, often discussed via CAP.
- Business consistency, meaning “customers and auditors accept the outcome”.
CAP is useful as a reminder that networks partition, and that distributed systems make trade offs under failure. But CAP does not tell you what your enterprise should accept. That is a product and risk decision.
Here is the decision framework I use in steering committees. Treat these as sub questions that must be answered in order:
- Sub question 1: What is the customer harm if this data is stale for 5 minutes, 1 hour, 1 day.
- Sub question 2: What is the regulatory harm if this data is temporarily inconsistent across systems.
- Sub question 3: What is the operational harm if we need manual reconciliation.
- Sub question 4: What is the commercial upside of decoupling, meaning faster change, lower lead time, reduced blast radius.
Once you answer those, you can select one of four practical consistency positions, per business capability:
- Strong consistency: read your writes is guaranteed, often via a single system of record and synchronous flows for critical steps.
- Bounded staleness: data can be behind, but within a defined time window and monitored.
- Eventual consistency: the system converges, but you invest in compensations and reconciliation.
- Probabilistic consistency: you accept rare anomalies and focus on detection and remediation. This is appropriate only when customer harm is low.
A strong opinion: “eventual consistency” is acceptable only when you can describe your compensation path in one sentence. If you cannot, you are not choosing eventual consistency. You are gambling.
Now add scale reality. IDC’s global datasphere projection is not just trivia. It tells you the direction of travel: more data, more replication, more integration points. That makes uncontrolled eventual consistency progressively harder to operate.
Replacing distributed transactions: patterns that work in production
In a monolith, cross module changes often sit inside one database transaction. In microservices, traditional distributed transactions such as two phase commit tend to be brittle and operationally heavy. The alternative is not “no consistency”. The alternative is explicit workflow patterns that make the business outcome resilient.
The three patterns that consistently work are:
1) Saga for business transactions
A saga decomposes a business transaction into local transactions, with compensating actions when a later step fails. Microsoft’s Azure Architecture Center describes the saga pattern specifically as a way to manage data consistency when ACID does not span multiple independent stores.
Key guardrails for sagas:
- Define the pivot point, meaning the step after which you compensate rather than roll back.
- Make every command idempotent, using idempotency keys.
- Implement timeouts and dead letter handling as first class operational features, not afterthoughts.
Failure mode to watch: “compensation theatre”, where compensations exist on paper but cannot run safely because downstream side effects are irreversible. If you cannot compensate, you must redesign the workflow, often by delaying commitment, or by using reservation semantics.
2) Transactional outbox for reliable event publishing
If you publish events from a service, you need delivery guarantees that align with your local write. The common approach is a transactional outbox table written in the same local transaction as the business change, then asynchronously dispatched. This is how you avoid phantom events and missing events, which are the twin enemies of eventual consistency.
Failure mode to watch: outbox backlog grows, and “eventual” becomes “never”. Treat dispatch lag as an SLO.
3) CQRS only where read models truly differ
CQRS can be valuable when you need separate read models for performance or user experience. But it increases data duplication, and therefore the operational surface area of eventual consistency. Use it where the read side is materially different and worth the complexity.
Failure mode to watch: teams use CQRS to avoid hard domain decisions, and end up with many projections, no ownership, and no reconciliation strategy.
Implementation approach: phased execution with governance guardrails
A safe implementation approach usually follows four phases:
- Baseline and classify data
Map domains and classify datasets into strong consistency, bounded staleness, and eventual consistency groups. Define RTO and RPO expectations per capability. - Build the reliability spine
Before scaling services, standardise eventing, idempotency, schema versioning, and a minimal observability stack. More than two thirds of organisations use Prometheus in production in some capacity, and 41 percent use OpenTelemetry in production, which reflects where the ecosystem is consolidating. - Pilot one end to end business journey
Pick one journey, for example order to cash, or onboarding. Implement saga, outbox, and reconciliation. Instrument the lag and error budget. - Scale with a platform and operating model
This is where most programmes stall. You need ownership, on call, and change governance that matches the distributed architecture.
Typical pitfalls:
- Shared databases that re create coupling.
- “Events everywhere” with no contract governance.
- Ignoring data deletion and retention obligations across replicas.
Operating model, security, and governance: what must change
Microservices move complexity from code structure to organisational coordination. You cannot keep the monolith era operating model and expect distributed data to behave.
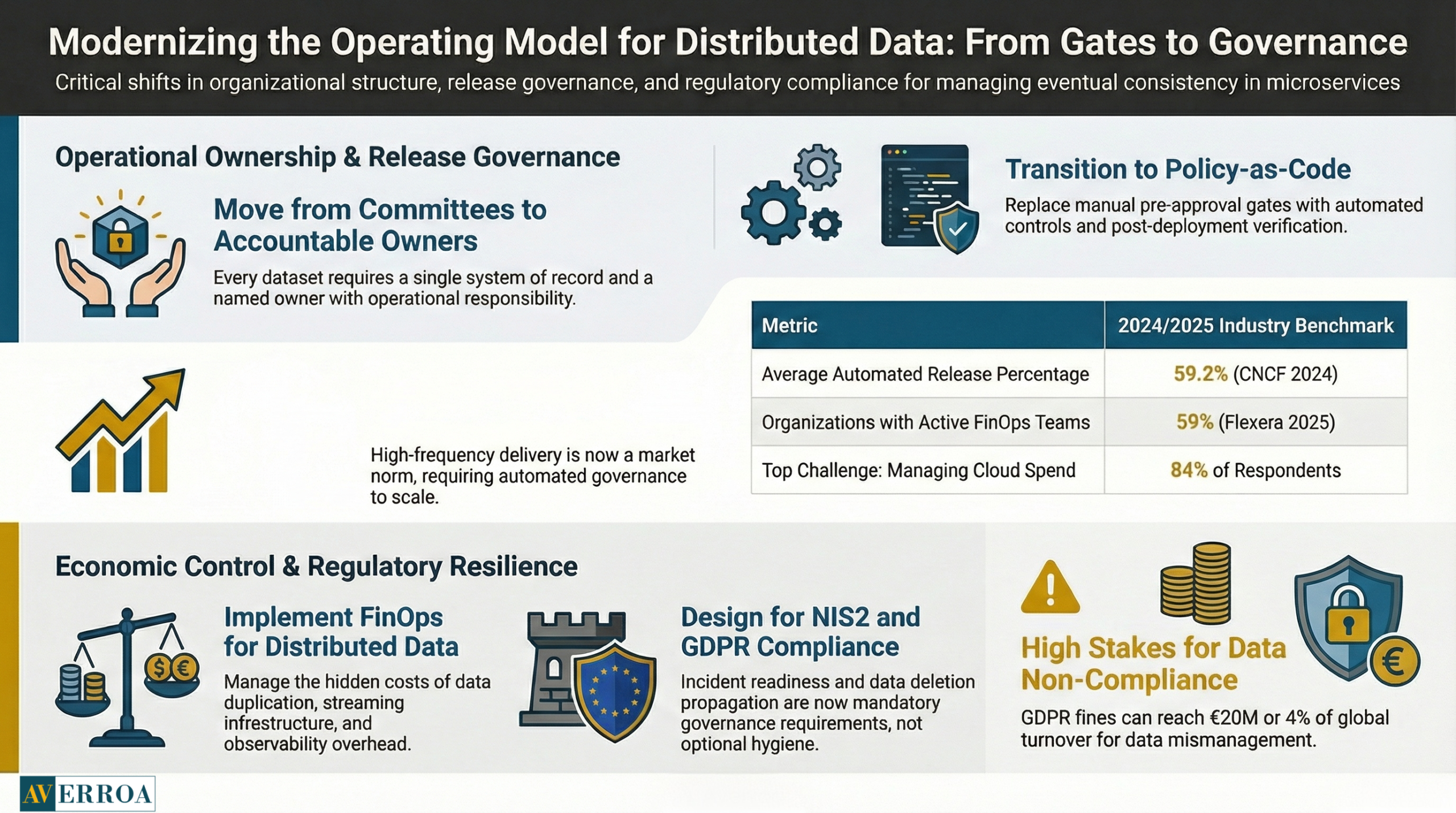
Ownership and decision rights
Every dataset needs a system of record and an accountable owner. Not a committee. An owner with operational responsibility. This matters most for eventual consistency flows because someone must own reconciliation outcomes.
Release governance that matches the architecture
If you are decomposing, you will ship more frequently. That is the point. The CNCF Annual Survey 2024 shows an average automated release percentage of 59.2 percent, and 38 percent of respondents said 80 to 100 percent of their releases are automated. This is a market signal. High frequency delivery is now normal. Your governance must shift from pre approval gates to automated controls, policy as code, and post deployment verification.
Spend control and platform economics
Distributed data introduces duplication, streaming infrastructure, and observability overhead. Flexera’s 2025 State of the Cloud findings show 84 percent of respondents cite managing cloud spend as a top challenge, and the proportion reporting a FinOps team doing some or all cost optimisation tasks rose from 51 percent to 59 percent. If you ignore this, eventual consistency becomes expensive consistency, because you pay twice for data storage, and three times for the people needed to operate it.
Regulatory alignment for EU and MENA contexts
Even if your organisation is not EU headquartered, if you process EU resident data you are in scope for GDPR enforcement. The GDPR fine framework can reach €20 million or 4 percent of global annual turnover, whichever is higher. This matters in microservices because personal data spreads across multiple stores and pipelines. Data minimisation and deletion must be designed, not hand waved.
On resilience expectations, the European Commission notes that member states had until 17 October 2024 to transpose NIS2 into national law. For leaders, the practical implication is simple: incident readiness and system visibility are no longer optional hygiene. They are governance requirements. Eventual consistency increases the need for fast detection, clear ownership, and rehearsed response.
Anonymised example: a financial services organisation introduced microservices for onboarding and risk checks. They used asynchronous events to keep UI latency low. Under load, duplicate events triggered duplicate checks, and the compliance team saw inconsistent audit trails across systems. The remediation was to introduce idempotency keys at the gateway, a saga orchestrator with persistent state, and an audit event stream with strict schema governance. The bigger change was establishing a “data control owner” role for critical workflows, with weekly reconciliation reporting to the programme director.
KPIs and value realisation: measure what executives care about
Microservices programmes get funded on agility and resilience. Distributed data can either enable that, or silently erode it. Use KPIs that force honesty.
Core operational KPIs
- Mean time to recovery and incident rate for data pipelines. CircleCI’s 2024 delivery analysis reports a median recovery from errors in under 60 minutes for the first time in the report’s history. Use this as a benchmark direction, not as a universal target.
- Event lag SLO, for example “95 percent of events applied within 2 minutes”.
- Reconciliation backlog, meaning number of records requiring manual or automated correction.
Business outcome KPIs
- Customer visible error rate, such as failed checkouts, duplicate notifications, or delayed fulfilment.
- Financial leakage, such as oversell cost, chargeback rates, or compensation payouts.
- Compliance control effectiveness, measured by audit exceptions and time to produce an end to end trace.
Delivery KPIs
- Automated release coverage and change failure rate. The CNCF automation numbers are a reminder that manual release processes do not scale in a distributed world.
- Lead time for changes in one domain, which is the actual promise of microservices.
A strong opinion: if you cannot demonstrate improved recovery, improved release safety, and stable reconciliation within two quarters, you should pause service proliferation and invest in the reliability spine. Outage economics are not forgiving.
Actionable Takeaways
- Treat eventual consistency as a business policy, with explicit time windows and customer recovery paths.
- Classify datasets into strong consistency, bounded staleness, and eventual consistency before you decompose services.
- Use saga plus compensations for business transactions, and test compensations like production code.
- Standardise idempotency keys and an outbox pattern early, or your eventing will become ungovernable.
- Make event lag and reconciliation backlog first class SLOs, with named owners.
- Invest in observability as a prerequisite, not as a late phase nice to have.
- Align release governance to automation and verification, not manual gates.
- Build FinOps into the platform plan, because distributed data multiplies spend drivers.
- If critical data cannot be consistently correct when it must be, keep that capability closer to a single system of record and modernise around it.
If you are modernising enterprise platforms and workflow heavy operations, and you want microservices benefits without data chaos, explore Averroa’s enterprise workflow automation services and delivery approach here.
References
- IBM, Cost of a Data Breach 2024, financial industry summary (2024)
- Uptime Institute, Annual Outage Analysis 2024, key findings (27 Mar 2024)
- Uptime Institute, Executive summary PDF, preventability and cost stats (2024)
- CNCF, Annual Survey 2024 report PDF, release automation stats (Apr 2025 publication)
- Grafana Labs, Observability Survey Report 2025, Prometheus and OpenTelemetry adoption (2025)
- CircleCI, The 2024 State of Software Delivery report PDF (2024)
- Seagate and IDC, The Digitization of the World From Edge to Core, datasphere forecast PDF (2018)
- European Commission, NIS2 Directive policy page, transposition deadline (2024)
- European Commission, GDPR sanctions, fine ceiling summary (accessed 2026)
- Microsoft, Saga design pattern, Azure Architecture Center (accessed 2026)
- Flexera, 2025 State of the Cloud report page, FinOps team uptake (2025)
Data Is the Hard Part: Eventual Consistency and Distributed Transactions
If you are migrating from a monolith to microservices, the hard part is not the APIs or the containers. It is the data. Specifically, it is how you maintain trust in your numbers when you no longer have one database, one transaction boundary, and one place to “just fix it”.
This matters now because most enterprises are scaling digital operations under tighter resilience and compliance expectations. In the EU, NIS2 raised the bar on operational risk and incident readiness, with member state transposition due by 17 October 2024. Meanwhile, data volumes and system interdependence keep rising, which increases the blast radius of “small” inconsistencies. IDC forecasts the global datasphere growing to 175 zettabytes by 2025.
Eventual consistency is therefore not a technical footnote. It is a business policy decision about what can be temporarily wrong, for how long, and with what customer and regulatory consequences. If you do not make that decision explicitly, the system will make it for you, usually during an incident.
Why distributed data breaks programmes, not code
Microservices migration programmes rarely fail because a team cannot build services. They fail because the organisation ships an operating model that cannot run distributed data safely.
Start with the board level risk statement. Outages and data incidents are expensive and reputation compounding. In Uptime Institute’s Annual Outage Analysis 2024, 54 percent of respondents said their most recent significant outage cost more than $100,000, and 16 percent said it cost more than $1 million. Even more pointed, four in five respondents said their most recent serious outage could have been prevented with better practices. This is not a tooling problem. It is governance and execution discipline.
Then add breach exposure. IBM’s Cost of a Data Breach findings for 2024 put the average global breach cost at USD 4.88 million. In microservices, data is replicated, cached, streamed, and transformed across boundaries. If you do not control lineage and access consistently, you multiply audit scope and increase the chance that an operational mistake becomes a compliance event.
A practical way to frame this for decision makers is to ask one uncomfortable question: which numbers must never be wrong, even briefly. Payroll, entitlements, payment status, sanctions screening, clinical safety flags, and regulated reporting fields usually sit in this category. If you cannot ring fence those “must be right now” datasets, your migration sequencing is wrong.
Anonymised example: a regional retailer decomposed its monolith into services and kept “inventory” as an event fed projection for speed. That worked until promotions. During peak load, consumers saw items as “in stock” that were already reserved. The technical issue was lag and duplicate event processing. The business issue was that the organisation had never agreed an acceptable oversell rate, nor a customer recovery playbook. They ended up re introducing synchronous checks for specific SKUs and created a nightly reconciliation job with a clear operational owner. The fix was not heroic engineering. It was making data policy explicit.
Eventual consistency without dogma: choose it, do not inherit it
Eventual consistency is often sold as a modern architecture badge. In reality, it is a trade. You are paying with temporary inconsistency to buy availability, latency, autonomy, and deployability.
To keep the discussion grounded, align on three meanings of “consistency” that executives often mix up:
- Transactional consistency inside one database, usually ACID.
- Distributed systems consistency trade offs, often discussed via CAP.
- Business consistency, meaning “customers and auditors accept the outcome”.
CAP is useful as a reminder that networks partition, and that distributed systems make trade offs under failure. But CAP does not tell you what your enterprise should accept. That is a product and risk decision.
Here is the decision framework I use in steering committees. Treat these as sub questions that must be answered in order:
- Sub question 1: What is the customer harm if this data is stale for 5 minutes, 1 hour, 1 day.
- Sub question 2: What is the regulatory harm if this data is temporarily inconsistent across systems.
- Sub question 3: What is the operational harm if we need manual reconciliation.
- Sub question 4: What is the commercial upside of decoupling, meaning faster change, lower lead time, reduced blast radius.
Once you answer those, you can select one of four practical consistency positions, per business capability:
- Strong consistency: read your writes is guaranteed, often via a single system of record and synchronous flows for critical steps.
- Bounded staleness: data can be behind, but within a defined time window and monitored.
- Eventual consistency: the system converges, but you invest in compensations and reconciliation.
- Probabilistic consistency: you accept rare anomalies and focus on detection and remediation. This is appropriate only when customer harm is low.
A strong opinion: “eventual consistency” is acceptable only when you can describe your compensation path in one sentence. If you cannot, you are not choosing eventual consistency. You are gambling.
Now add scale reality. IDC’s global datasphere projection is not just trivia. It tells you the direction of travel: more data, more replication, more integration points. That makes uncontrolled eventual consistency progressively harder to operate.
Replacing distributed transactions: patterns that work in production
In a monolith, cross module changes often sit inside one database transaction. In microservices, traditional distributed transactions such as two phase commit tend to be brittle and operationally heavy. The alternative is not “no consistency”. The alternative is explicit workflow patterns that make the business outcome resilient.
The three patterns that consistently work are:
1) Saga for business transactions
A saga decomposes a business transaction into local transactions, with compensating actions when a later step fails. Microsoft’s Azure Architecture Center describes the saga pattern specifically as a way to manage data consistency when ACID does not span multiple independent stores.
Key guardrails for sagas:
- Define the pivot point, meaning the step after which you compensate rather than roll back.
- Make every command idempotent, using idempotency keys.
- Implement timeouts and dead letter handling as first class operational features, not afterthoughts.
Failure mode to watch: “compensation theatre”, where compensations exist on paper but cannot run safely because downstream side effects are irreversible. If you cannot compensate, you must redesign the workflow, often by delaying commitment, or by using reservation semantics.
2) Transactional outbox for reliable event publishing
If you publish events from a service, you need delivery guarantees that align with your local write. The common approach is a transactional outbox table written in the same local transaction as the business change, then asynchronously dispatched. This is how you avoid phantom events and missing events, which are the twin enemies of eventual consistency.
Failure mode to watch: outbox backlog grows, and “eventual” becomes “never”. Treat dispatch lag as an SLO.
3) CQRS only where read models truly differ
CQRS can be valuable when you need separate read models for performance or user experience. But it increases data duplication, and therefore the operational surface area of eventual consistency. Use it where the read side is materially different and worth the complexity.
Failure mode to watch: teams use CQRS to avoid hard domain decisions, and end up with many projections, no ownership, and no reconciliation strategy.
Implementation approach: phased execution with governance guardrails
A safe implementation approach usually follows four phases:
- Baseline and classify data
Map domains and classify datasets into strong consistency, bounded staleness, and eventual consistency groups. Define RTO and RPO expectations per capability. - Build the reliability spine
Before scaling services, standardise eventing, idempotency, schema versioning, and a minimal observability stack. More than two thirds of organisations use Prometheus in production in some capacity, and 41 percent use OpenTelemetry in production, which reflects where the ecosystem is consolidating. - Pilot one end to end business journey
Pick one journey, for example order to cash, or onboarding. Implement saga, outbox, and reconciliation. Instrument the lag and error budget. - Scale with a platform and operating model
This is where most programmes stall. You need ownership, on call, and change governance that matches the distributed architecture.
Typical pitfalls:
- Shared databases that re create coupling.
- “Events everywhere” with no contract governance.
- Ignoring data deletion and retention obligations across replicas.
Operating model, security, and governance: what must change
Microservices move complexity from code structure to organisational coordination. You cannot keep the monolith era operating model and expect distributed data to behave.
Ownership and decision rights
Every dataset needs a system of record and an accountable owner. Not a committee. An owner with operational responsibility. This matters most for eventual consistency flows because someone must own reconciliation outcomes.
Release governance that matches the architecture
If you are decomposing, you will ship more frequently. That is the point. The CNCF Annual Survey 2024 shows an average automated release percentage of 59.2 percent, and 38 percent of respondents said 80 to 100 percent of their releases are automated. This is a market signal. High frequency delivery is now normal. Your governance must shift from pre approval gates to automated controls, policy as code, and post deployment verification.
Spend control and platform economics
Distributed data introduces duplication, streaming infrastructure, and observability overhead. Flexera’s 2025 State of the Cloud findings show 84 percent of respondents cite managing cloud spend as a top challenge, and the proportion reporting a FinOps team doing some or all cost optimisation tasks rose from 51 percent to 59 percent. If you ignore this, eventual consistency becomes expensive consistency, because you pay twice for data storage, and three times for the people needed to operate it.
Regulatory alignment for EU and MENA contexts
Even if your organisation is not EU headquartered, if you process EU resident data you are in scope for GDPR enforcement. The GDPR fine framework can reach €20 million or 4 percent of global annual turnover, whichever is higher. This matters in microservices because personal data spreads across multiple stores and pipelines. Data minimisation and deletion must be designed, not hand waved.
On resilience expectations, the European Commission notes that member states had until 17 October 2024 to transpose NIS2 into national law. For leaders, the practical implication is simple: incident readiness and system visibility are no longer optional hygiene. They are governance requirements. Eventual consistency increases the need for fast detection, clear ownership, and rehearsed response.
Anonymised example: a financial services organisation introduced microservices for onboarding and risk checks. They used asynchronous events to keep UI latency low. Under load, duplicate events triggered duplicate checks, and the compliance team saw inconsistent audit trails across systems. The remediation was to introduce idempotency keys at the gateway, a saga orchestrator with persistent state, and an audit event stream with strict schema governance. The bigger change was establishing a “data control owner” role for critical workflows, with weekly reconciliation reporting to the programme director.
KPIs and value realisation: measure what executives care about
Microservices programmes get funded on agility and resilience. Distributed data can either enable that, or silently erode it. Use KPIs that force honesty.
Core operational KPIs
- Mean time to recovery and incident rate for data pipelines. CircleCI’s 2024 delivery analysis reports a median recovery from errors in under 60 minutes for the first time in the report’s history. Use this as a benchmark direction, not as a universal target.
- Event lag SLO, for example “95 percent of events applied within 2 minutes”.
- Reconciliation backlog, meaning number of records requiring manual or automated correction.
Business outcome KPIs
- Customer visible error rate, such as failed checkouts, duplicate notifications, or delayed fulfilment.
- Financial leakage, such as oversell cost, chargeback rates, or compensation payouts.
- Compliance control effectiveness, measured by audit exceptions and time to produce an end to end trace.
Delivery KPIs
- Automated release coverage and change failure rate. The CNCF automation numbers are a reminder that manual release processes do not scale in a distributed world.
- Lead time for changes in one domain, which is the actual promise of microservices.
A strong opinion: if you cannot demonstrate improved recovery, improved release safety, and stable reconciliation within two quarters, you should pause service proliferation and invest in the reliability spine. Outage economics are not forgiving.
Actionable Takeaways
- Treat eventual consistency as a business policy, with explicit time windows and customer recovery paths.
- Classify datasets into strong consistency, bounded staleness, and eventual consistency before you decompose services.
- Use saga plus compensations for business transactions, and test compensations like production code.
- Standardise idempotency keys and an outbox pattern early, or your eventing will become ungovernable.
- Make event lag and reconciliation backlog first class SLOs, with named owners.
- Invest in observability as a prerequisite, not as a late phase nice to have.
- Align release governance to automation and verification, not manual gates.
- Build FinOps into the platform plan, because distributed data multiplies spend drivers.
- If critical data cannot be consistently correct when it must be, keep that capability closer to a single system of record and modernise around it.
If you are modernising enterprise platforms and workflow heavy operations, and you want microservices benefits without data chaos, explore Averroa’s enterprise workflow automation services and delivery approach here.
References
- IBM, Cost of a Data Breach 2024, financial industry summary (2024)
- Uptime Institute, Annual Outage Analysis 2024, key findings (27 Mar 2024)
- Uptime Institute, Executive summary PDF, preventability and cost stats (2024)
- CNCF, Annual Survey 2024 report PDF, release automation stats (Apr 2025 publication)
- Grafana Labs, Observability Survey Report 2025, Prometheus and OpenTelemetry adoption (2025)
- CircleCI, The 2024 State of Software Delivery report PDF (2024)
- Seagate and IDC, The Digitization of the World From Edge to Core, datasphere forecast PDF (2018)
- European Commission, NIS2 Directive policy page, transposition deadline (2024)
- European Commission, GDPR sanctions, fine ceiling summary (accessed 2026)
- Microsoft, Saga design pattern, Azure Architecture Center (accessed 2026)
- Flexera, 2025 State of the Cloud report page, FinOps team uptake (2025)
Meet The Author
Meet The Author

Senior software engineer focused on backend systems and Android apps, delivering scalable web/mobile/cloud solutions. Leads technical direction, mentors teams, and ships high-performance services using ASP.NET Core/C#, microservices, and cloud-native infrastructure.
Senior software engineer focused on backend systems and Android apps, delivering scalable web/mobile/cloud solutions. Leads technical direction, mentors teams, and ships high-performance services using ASP.NET Core/C#, microservices, and cloud-native infrastructure.
Averroa Principal
Table of content
- Data Is the Hard Part: Eventual Consistency and Distributed Transactions
- Why distributed data breaks programmes, not code
- Eventual consistency without dogma: choose it, do not inherit it
- Replacing distributed transactions: patterns that work in production
- Implementation approach: phased execution with governance guardrails
- Operating model, security, and governance: what must change
- KPIs and value realisation: measure what executives care about
- Actionable Takeaways
- References